本章主要是从程序设计人员角度对UNIX系统的一些术语和概念有一个大概的印象。
UNIX体系结构
首先看下UNIX操作系统的体系及构图: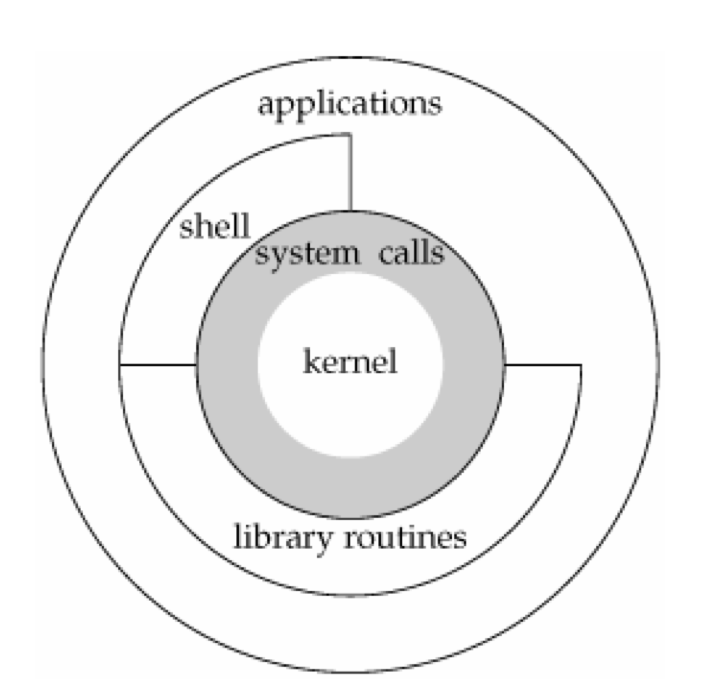
从图的内往外看
- 第一层是内核(kernel),它是系统软件,控制计算机的硬件资源,提供程序运行环境。
第二层是系统调用(system call),所有的系统调用都要通过它来实现。
第三层比较复杂了,主要有库函数(library routines),shell和应用软件(application)。应用软件可以调用库函数,也可以直接调用系统函数,shell则是一种特殊的应用软件。
登录
用过unix系统的都知道,当开机首先会让输入用户名和密码才能进入系统,其实在unix系统开机后首先运行登录程序/bin/login(关于unix从开机到进入系统的过程,先参考阮一峰的这篇博客:linux的启动流程, 稍后做一下补充),然后读取/etc/passwd文件,验证用户名密码是否正确。
这个passwd文件由7个以冒号分割的字段组成,举个例子:sean:x:504:505::/home/sean:/bin/bash
这七个字段分别是:
登录名:加密口令:数值用户ID:数值组ID:注释字段:起始目录:shell程序
ps:加密口令单数放在一个文件里面,第六章会对其进行介绍
输入和输出
- 文件描述符:内核用来标识一个特定进程正在访问的文件的非负整数。
- 标准输入、标准输出和标准出错:运行一个新程序shell都会为其打开这三个文件描述符。
- 不用缓冲的I/O:程序直接对输入输出进行处理。
- 标准I/O:需要先输入输出到缓冲区,然后按照某种策略中缓冲区中输出。
ps:具体的过程后面会讲到。
程序和进程
- 程序:是存放在磁盘上、处于某个目录中的一个可执行文件。使用6个exec函数中的一个由内核将程序读入存储器,并使其执行。
进程和进程ID:程序的执行实例被称为进程(process)。某些操作系统使用任务(task)表示。UNIX系统确保每个进程都有一个唯一的数字标志符,称为进程ID(process ID)。进程ID总是非负数。
1
2
3
4
5
6
7
8#include "apue.h"
int
main(void)
{
printf("hello world from process ID %d\n", getpid());
exit(0);
}1
2
3
4
5$ ./a.out
hello world from precess ID 851
$ ./a.out
hello world from precess ID 854- 进程控制:有三个用于进程控制的主要函数:fork, exec和waitpid。
- fork:调用fork创建一个新进程。新进程是调用进程的复制品,我们称调用进程为父进程,新创建的进程为子进程。fork向父进程返回新子进程的进程ID,对子进程返回0。因为fork创建一新进程,所以它被调用一次(由父进程),但返回两次(分别是在父进程及子进程中)。
- 线程和线程ID:为了充分利用对处理器系统的并行性,可以使用多线程(thread)。在一个进程内的所有线程同享统一地址空间、文件描述符、栈以及于进程相关的属性。因为它们能访问统一存储区,所以各线程在访问共享数据时需要采取同步措施以避免不一致性。与进程相同,线程也用ID标识,但是,线程ID只在它所属的进程内起作用。
出错处理
当UNIX函数出错时,常常返回一个负值,而且整型变量errno通常被设置为含有附加信息的一个值。例如open函数如果执行错误则返回-1。在open出错时,有大约15种不同的errno值(文件不存在、权限问题等)。某些函数并不返回负值而是使用另一种约定。
可以将<errno.h>中定义的各种出错分成致命性的和非致命性的两类。对于致命性的错误,无法执行恢复动作,最多只能在用户屏幕上打印出一条出错消息,或者将一条出错消息写如日志文件中,然后终止。对于非致命性的出错,有时可以较妥善地进行处理。大多数非致命性的出错在本质上时暂时的,例如资源短缺,当系统中的活动较少时,这种出错很可能不会发生。
用户标识
- 用户ID:口令文件登录项中的用户ID(user ID)是一个数值,它向系统标识各个不同的用户。用户ID为0的用户为根(root)或超级用户(superuser)。
- 组ID:口令文件登录项也包括用户的组ID(group ID),它是一个数值。组ID也是由系统管理员在指定用户登录名时分配的。下面就是获取用户ID和组ID的例子:
1
2
3
4
5
6
7
8# include "apue.h"
int
main(void)
{
printf("uid = %d, gid = %d\n", getuid(), getgid());
exit(0);
}1
2$ ./a.out
uid = 205, gid = 105 - 附加组ID:除了在口令文件中对一个登录名执行一个组ID外,大多数UNIX系统版本还允许一个用户属于另外的组。这就是附加组ID(supplementary group ID)。通过读取
/etc/group获得。
信号
信号(signal)是通知进程已经发生某种情况的一种技术。进程如何处理信号由三种选择:
- 忽略该信号。
- 按系统默认方式处理。
- 提供一个函数,信号发生时则调用该函数,这被称为捕捉该信号。使用这种方式,我们要提供自编的函数就将能知道什么时候产生了信号,并按所希望的方式处理它。
很多情况会产生信号,比如终端键盘上有两种产生信号的方法,分别称为中断键(interrupt key, 通常是Delete键或Ctrl+ C)和退出键(quit key, 通常是Ctrl+)。另外一种产生信号的方法是调用名为kill的函数,在一个进程中调用该函数就可以向另外一个进程发送一个信号。
时间值
UNIX系统一直使用两种不同的时间值:
- 日历时间:该值是自1970年1月1日00:00:00以来国际标准时间(UTC)所经过的秒数累计值。系统基本数据类型为time_t用户保存这种时间值。
- 进程时间:这也被称为CPU时间,用以度量进程使用的中央处理机资源。进程时间以时钟滴答计算,历史上曾经取50、60和100个滴答。系统基本数据类型clock_t用于保存这种时间值。
当度量一个进程的执行时间时,UNIX系统使用三个进程时间值:
- 时钟时间:又称为墙上时钟时间(wall clock time)。它是进程运行的时间总量,其值与系统中同时运行的进程数有关。
- 用户CPU时间:是执行用户指令所用的时间。
- 系统CPU时间:是为该进程执行内核程序所经历的时间。
用户CPU时间 + 系统CPU时间 = CPU时间。
时钟时间 = CPU时间 + 其它等待的时间。
系统调用和库函数
所有的操作系统都提供多种服务的入口点,程序由此向内核请求服务。这些入口点被称为系统调用。
UNIX所使用的技术是为每个系统调用在标准C库中设置一个具有同样名字的函数。用户进程用标准C调用序列来调用这些函数,然后,函数又用系统所要求的技术调用相应的内核服务。从应用的角度考虑,可将系统调用视作为C函数。从实现者的角度观察,系统调用和库函数之间有重大区别;但从用户角度看,其区别并不非常重要。系统调用通常提供一种最小接口,而库函数通常提供比较复杂的功能。
图1-2 malloc函数和sbrk系统调用
图1-3 C库函数和系统调用之间的差别
习题
1.3 在1.7节中,perror的参数是用ISO C的属性const定义的,而strerror的整型参数则没有用此属性定义,为什么?
2
3
4
5
char *strerror(int errnum);
# include <stdio.h>
void perror(const char *msg);
下面先看这两个函数的使用方式:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# include <stdio.h>
int main ()
{
FILE * pFile;
pFile=fopen ("unexist.ent","rb");
if (pFile==NULL)
perror ("The following error occurred");
else
fclose (pFile);
return 0;
}
/*
out put;
The following error occurred: No such file or directory
*/
/* strerror example : error list */
# include <stdio.h>
# include <string.h>
# include <errno.h>
int main ()
{
FILE * pFile;
pFile = fopen ("unexist.ent","r");
if (pFile == NULL)
printf ("Error opening file unexist.ent: %s\n",strerror(errno));
return 0;
}
/*
out put:
Error opening file unexist.ent: No such file or directory
*/
可见perror的参数是程序运行前就定义好的,其输出是先输出msg指向的字符串,然后加上errno值对应的出错信息。
而strerror的参数是运行时确定的,是一个errno的值,其输出是errno对应的出错信息.
所以perror的参数带const而strerror的参数不带const。