*本章是理解程序如何运行的关键所在,这一章将学到:
- 程序时如何从高级代码变为汇编代码;
- 程序编译后运行时在内存中是如何分布的;
3…*
程序代码
首先介绍各种单片机、处理器,不同的处理器所使用的能够识别的汇编语言也是不一样的,如何根据不同处理器把同一段高级语言转换成对应的汇编语言,这个是编译器的事儿,本文所有的汇编语言我的机器就跟他不同,导致我学习的时候也为此很头疼,严重影响了我对本来就一知半解的汇编语言的理解。
程序编码
在深入了解程序代码之前需要简单的了解一下GCC编译器的使用方法。
首先编写一个简单的C文件:code.c1
2
3
4
5
6
7
8
9 //code.c
int accum = 0;
int sum(int x, int y)
{
int t = x + y;
accum += t;
return t;
}
然后利用gcc命令加上-S参数生产一个汇编代码文件:1
2
3
4gcc -O1 -S code.c
ll
code.c
code.s
可见生成了一个.s文件,打开这个汇编文件,内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 .file"code.c"
.text
.globl sum
.type sum, @function
sum:
.LFB0:
.cfi_startproc
leal (%rsi,%rdi), %eax
addl %eax, accum(%rip)
ret
.cfi_endproc
.LFE0:
.size sum, .-sum
.globl accum
.bss
.align 4
.type accum, @object
.size accum, 4
accum:
.zero4
.ident "GCC: (GNU) 4.4.6 20110731 (Red Hat 4.4.6-3)"
.section .note.GNU-stack,"",@progbits
但是书中给出的生成的代码却是这样的:1
2
3
4
5
6
7
8sum:
pushl %ebp
movl %esp, %ebp
movl 12(%ebp), %eax
addl 8(%ebp), %eax
addl %eax, accum
popl %ebp
ret
可以看到这两段代码差别很大,这是因为所在的处理器环境不同,所以汇编命令格式会有差别;而且gcc的版本也不同,会导致优化的程度也不同。为了能够更好的理解课本,以后就按照书上的来理解。
如果在使用gcc的时候加-C参数,则汇编器会把汇编文件编译成二进制文件:1
gcc -O1 -c code.c
这是生产了code.o文件,但是它的内容是二进制的,直接看不到。用vi打开文件,然后在normal模式下输入::%!xxd1
2
3
4
5
6
7
8
9
10
110000000: 7f45 4c46 0201 0100 0000 0000 0000 0000 .ELF............
0000010: 0100 3e00 0100 0000 0000 0000 0000 0000 ..>.............
0000020: 0000 0000 0000 0000 1001 0000 0000 0000 ................
0000030: 0000 0000 4000 0000 0000 4000 0c00 0900 ....@.....@.....
0000040: 8d04 3e01 0500 0000 00c3 0000 0047 4343 ..>..........GCC
0000050: 3a20 2847 4e55 2920 342e 342e 3620 3230 : (GNU) 4.4.6 20
0000060: 3131 3037 3331 2028 5265 6420 4861 7420 110731 (Red Hat
0000070: 342e 342e 362d 3329 0000 0000 0000 0000 4.4.6-3)........
0000080: 1400 0000 0000 0000 017a 5200 0178 1001 .........zR..x..
0000090: 1b0c 0708 9001 0000 1400 0000 1c00 0000 ................
......
还可以通过gdb这个调试工具进行查看二进制文件:1
2
3
4$gbd code.o
(gdb) x/17xb sum
0x0 <sum>:0x8d0x040x3e0x010x050x000x000x 00
0x8 <sum+8>:0x000xc3Cannot access memory at address 0xa
但是要查看目标代码文件的内容,最有价值的还是反汇编器(disassembler),这玩意儿听上去就很NB有木有?使用方法入下:1
2
3
4
5
6
7
8
9
10objdump -d code.o
code.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <sum>:
0:8d 04 3e lea (%r si,%rdi,1),%eax
3:01 05 00 00 00 00 add %eax,0x0(%rip) # 9 <sum+0x9>
9:c3 retq
这个是我电脑上的结果,跟书上的有不一样,书上的是:1
2
3
4
5
6
7
8
9
10
11Disassembly of funciton sum in binary file code.o
00000000 <sum>
Offset Bytes Equivalent assembly language
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 8b 45 0c mov 0xc(%ebp),%eax
6: 03 45 08 add 0x8(%ebp), %eax
9: 01 05 00 00 00 00 add %eax,0x0
f: 5d pop %ebp
10: c3 ret
生成实际可执行的代码需要对一组目标代码文件运行链接器,而这一组目标代码文件中必须含有一个main函数,假设文件main.c中有下面这样一个函数:1
2
3
4int main()
{
return sum(1,3)
}
然后用下面的方法生成可执行文件prog:1
gcc -O1 -o prog code.o main.c
看到生成了一个prog可执行文件,对其进行反编译1
objdump -d prog
可看到一大坨的汇编代码,但是其中有一段跟上面的代码一样
1 | objdump -d code.o |
这个是我电脑上的结果,跟书上的有不一样,书上的是:1
2
3
4
5
6
7
8
9
10
11Disassembly of funciton sum in binary file code.o
00000000 <sum>
Offset Bytes Equivalent assembly language
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 8b 45 0c mov 0xc(%ebp),%eax
6: 03 45 08 add 0x8(%ebp), %eax
9: 01 05 00 00 00 00 add %eax,0x0
f: 5d pop %ebp
10: c3 ret
生成实际可执行的代码需要对一组目标代码文件运行链接器,而这一组目标代码文件中必须含有一个main函数,假设文件main.c中有下面这样一个函数:1
2
3
4int main()
{
return sum(1,3)
}
然后用下面的方法生成可执行文件prog:1
gcc -O1 -o prog code.o main.c
看到生成了一个prog可执行文件,对其进行反编译1
objdump -d prog
可看到一大坨的汇编代码,但是其中有一段跟上面的代码一样1
2
3
4
5
60000000000400474 <sum>:
400474: 8d 04 3e lea (%rsi,%rdi,1),%eax
400477: 01 05 d3 03 20 00 add %eax,0x2003d3(%rip) # 600850 <accum>
40047d: c3 retq
40047e: 90 nop
40047f: 90 nop
与前面的代码对比差不多,但是其地址有明显的改变,应为第二段代码编译后说有的地址都是相对程序的地址指定了的。
访问信息
访问信息分为:操作数指示符、数据传送指令等操作。通过一个练习题来巩固一下操作数指示符:
例题3.1 假设下面的值存放在指明的存储器地址和寄存器中:
| 地址 | 值 |
|---|---|
| 0x100 | 0xFF |
| 0x104 | 0xAB |
| 0x108 | 0x13 |
| 0x10C | 0x11 |
| 寄存器 | 值 |
|---|---|
| %eax | 0x100 |
| %ecx | 0x1 |
| %edx | 0x3 |
填写下表,给出所示操作数的值。
| 操作数 | 值 | 思路 |
|---|---|---|
| %eax | 0x100 | 直接从上面获取寄存器的初始值 |
| 0x104 | 0xAB | 从上面表中获取0x104地址的值 |
| $0x108 | 0x108 | 立即数 |
| (%eax) | 0xFF | 先获取寄存器%eax的值0x100,然后在获取地址0x100对应的值,间接寻址 |
| 4(%eax) | 0xAB | (基址+偏移量)寻址:(4 + 0x100) = (0x104) = 0xAB |
| 9(%eax, %edx) | 0x11 | 变址寻址:(9 + %eax + %edx) = (0x10C) = 0x11 |
| 260(%ecx, %edx) | 0x13 | 变址寻址:(260 + %ecx + %edx) = (0x108) = 0x13 |
| 0xFC(, %ecx, 4) | 0xFF | 比例变址寻址:(0xFC + 0 + %ecx * 4) = (0xFC+0x4) = (0x100)=0xFF |
| (%eax, %edx, 4) | 0x11 | 比例变址寻址:(%eax + %edx * 4)=(0x10C)=0x11 |
栈操作说明:
通过书中图3.5可知,当push一个数值时,栈指针减小,向下移动;当pop一个数据时栈指针向上移动。一般用 %esp来存储栈指针的地址。
下面通过一个例子说明C语言中指针使用的方式,函数exchange代码如下:1
2
3
4
5
6
7
8
9
10int exchange(int *xp, int y)
{
int x = *xp;
*xp = y;
return x;
}
int a = 4;
int b = exchange(&a, 3);
printf("a = %d, b = %d\n", a, b);
这段代码会打印出:a = 3, b = 4
关键部分的汇编代码如下:1
2
3
4
5# xp地址的值存储在8(%ebp), y的值存储在12(%ebp)
movl 8(%ebp) %edx #获取xp地址的值,存储在%edx
movl (%edx), %eax #获取xp地址所指向的值赋予变量x,函数结束时返回这个值
movl 12(%ebp), %ecx #获取y的值,存储在%ecx
movl %ecx, (%edx) #%ecx的值存储在%edx所指向的值, 这时候*xp的值为y,xp地址的值没有变化
局部变量比如x,通常时保存在寄存器中。
算术和逻辑操作
加载有效地址
加载有效地址(load effective address)指令leal实际上是movl指令的变形。通过下面一个例子来说明它的含义:1
2
3# 假设%edx的值为x
movl 7(%edx, %edx, 4), %eax #计算7 + x + 4*x = 5x +7 那么%eax的值就是地址5x+7地址处所存储的值.
leal 7(%edx, %edx, 4), %eax #计算7 + x + 4*x = 5x +7 那么%eax的值就是地址的值5x+7,而不是这个地址存储的值.
一元操作和二元操作
如果一个操作只有一个操作数,既是源又是目的,这个操作就是一元操作。
如果一个操作有两个操作数,第二个操作数既是源又是目的,这个操作就是二元操作。
如下:
| 指令 | 效果 | 操作 |
|---|---|---|
| INC D | D <- D + 1 | 一元操作 |
| ADD S, D | D <- D + S | 二元操作 |
移位操作
| 类型 | 操作 | 命令 | 示意图 |
|---|---|---|---|
| 非循环移位 | 逻辑左移/算术左移 | SHL/SAL |  |
| 非循环移位 | 逻辑右移 | SHR |  |
| 非循环移位 | 算术右移 | SAR |  |
| 循环移位 | 不含进位位的循环左移 | ROL |  |
| 循环移位 | 不含进位位的循环右移 | ROR |  |
| 循环移位 | 含进位位的循环左移 | RCL |  |
| 循环移位 | 含进位位的循环右移 | RCR |  |
控制
条件码
除了整数寄存器,CPU还维护着一组单个位的条件码(codition code)寄存器,最常用的条件码有:
- CF:进位标志。最近的操作使最高位产生了进位。可以用来检测无符号操作数的溢出。
- ZF:零标志。最近的操作得出的结果为0。
- SF:符号标志。最近的操作得到的结果为负。
- OF:溢出标志。最近的操作导致一个补码溢出——正溢出或负溢出。
访问条件码
条件码通常不会直接读取常用的使用方法有三种:
- 可以根据条件码的某个组合,将一个字节设置为0或者1;
- 可以条件跳转到程序的某个其它部分;
- 可以有条件地传送数据.
对于第一种情况,举例说明一下:
| 指令 | 同义名 | 效果 | 设置条件 |
|---|---|---|---|
| sete D | setz | D<-ZF | 相等/零 |
| setne D | setnz | D<-~ZF | 不等/非零 |
| sets D | D<-SF | 负数 | |
| setns D | D<-~SF | 非负数 | |
| setg D | setnle | D<-~(SF ^ DF)&~ZF | 大于(有符号>) |
SET指令。每条指令根据条件码的某个组合将一个字节设置为0或者1,而不是直接访问条件码寄存器。
跳转指令及其编码
正常情况下,指令按照它们出现的顺序一条一条地执行。跳转(jump)指令会导致执行切换到程序中一个全新的位置。在汇编代码中,这些跳转的目的地通常用一个标号(label)指明。当执行与PC(程序计数器)相关的寻址时,程序计数器的值是跳转指令后面的那条指令的地址,而不是跳转指令本身的地址。例如一段汇编代码及其反汇编代码:1
2
3
4
5
6
7
8
9
10 jle .L2 #if <=, goto dest2
.l5: #dest1:
movl %edx, %eax
sar1 %eax
subl %eax, %edx
leal (%edx, %edx, 2), %edx
testl %edx, %edx
jg .L5 #if >, goto dest1
.L2: #dest2
movl %edx, %eax1
2
3
4
5
6
7
88: 7e 0d jle 17 <silly+0x17>
a: 89 d0 mov %edx, %eax
c: d1 f8 sar %eax
e: 29 c2 sub %eax, %edx
10: 8d 14 52 lea (%edx, %edx, 2), %edx
13: 85 d2 test %edx, %edx
15: 7f f3 jg a <silly+0xa>
17: 89 d0 mov %edx, %eax
我们看到在反汇编代码里的第一行,前面地址为0x8的地方,0x7e代表jle, 0xd代表要跳转的地址,但是对应的汇编地址却是0x17, 其实0x17是通过0x8处的0xd与下一行0xa的地址(正是PC程序计数器的值)相加得出的。
翻译条件分支
如何将条件表达式和语句从C语言翻译成机器代码,最常用的方式是结合有条件和无条件跳转。通过一个例子来说明:
a) 原始的C语言代码1
2
3
4
5
6int absdiff(int x , int y) {
if (x < y)
return y - x;
else
return x - y;
}
b) 与之等价的goto版本1
2
3
4
5
6
7
8
9
10
11int absdiff(int x , int y) {
int result;
if (x >= y)
goto x_ge_y;
result = y - x;
goto done;
x_ge_y:
result = x - y;
done:
return result;
}
1 | # x at %ebp + 8, y at %ebp + 12 |
循环
其实循环和条件分支所利用的都是jump指令和标记寄存器的值,这里就不再说明了。
条件传送指令
实现条件操作的传统方法是利用控制的条件转移。但是在现代处理器上,它可能会非常的低效率。数据的条件转移是一种替代的策略。这种方法先计算一个条件操作的两种结果,然后再根据条件是否满足选取一个。通过一个例子来说明:1
2
3int absdiff(int x , int y) {
return x < y ? y-x:x-y;
}
产生的汇编代码:1
2
3
4
5
6
7
8
9# x at %ebp + 8, y at %ebp + 12
movl 8(%ebp), %ecx #get x
movl 12(%ebp), %edx #get y
movl %edx, %ebx #copy y
subl %ecx, %ebx #compute y - x
movl %ecx, %eax #copy x
subl %edx, %eax #compute x - y, set as return value
cmpl %edx, %ecx #compare x:y
cmovl %ebx, %eax #if <, replace return value with y - x
注意这个与上面的翻译条件分支一节的汇编做比较。这种方式效率会更好。原因是跟第4章和第5章讲的处理器的结构有关系,处理器通过流水线(pipelining)来获得高性能。第二种方式可以把所有的指令都放入到流水线中,而第一种方式则需要根据条件判断哪个指令放入到流水线,从这点可以看出第二种方式总是能把指令都放入流水线中,保证了执行的效率。
switch语句
switch(开关)语句可以根据一个整数索引值进行多重分支(multi-way branching)。处理具有多种可能结果的测试时。这种语句特别有用。它们不仅提高了C代码的可读性,而且通过使用跳转表(jump table)这种数据结构使得实现更加高效。
过程
一个过程调用包括将数据(以过程参数和返回值的形式)和控制从代码的一部分传递到另一部分。另外,它还必须在进入时为过程的局部变量分配空间,并在退出时释放这些空间。数据传递、局部变量的分配和释放通过操纵程序栈来实现。
栈桢结构
为单个过程分配的那部分栈称为栈帧(stack frame)。寄存器%ebp为帧指针,而寄存器%esp为栈指针。栈帧结构(栈用来传递参数、存储返回信息、保存寄存器,以及本地存储)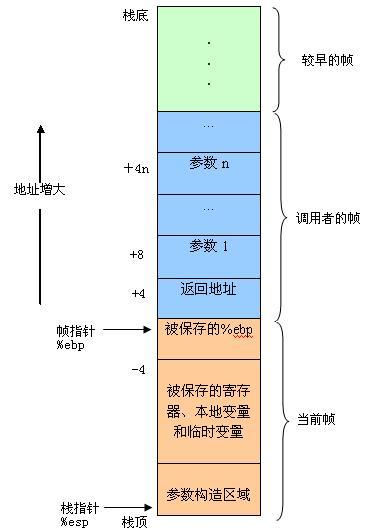
转移控制
支持过程调用和返回的指令:
| 指令 | 描述 |
|---|---|
| call Label | 过程调用 |
| call *Operand | 过程调用 |
| leave | 为返回准备栈 |
| ret | 从过程调用中返回 |
call指令的效果是将返回地址入栈,并跳转到被调用过程的起始处。返回地址是在程序中紧跟在call后面的那条指令地址。
例如: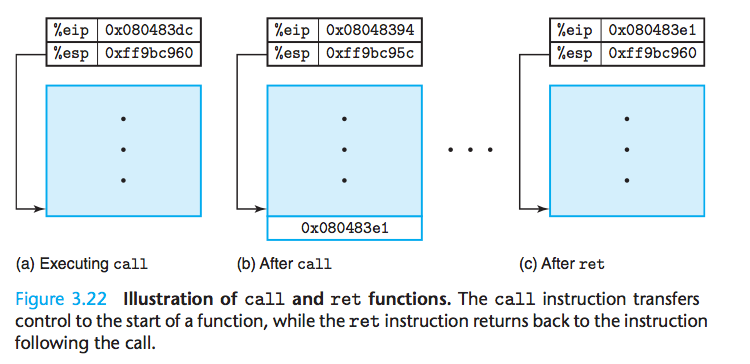
执行call的之后栈顶入栈的地址为call命令后那条命令的地址,然后ret执行后把这个地址弹出到%eip,开始执行%eip处的命令。%eip应该是程序计数器。还有一个要注意的是保存的%ebp,这个起始是上一个帧的起始地址,当前过程执行完后,这个保存的%ebp就会返回到%ebp中,更新当前帧的开始地址为上一帧的地址。
寄存器使用惯例
程序寄存器组是唯一能被所有过程共享的资源。虽然在给定时刻只能有一个过程是活动的,但是我们必须保证当一个过程(调用者)调用另一个过程(被调用者)时,被调用者不会覆盖某个调用者稍后会使用的寄存器的值。根据惯例,寄存器%eax、%edx和%ecx被划分为调用者保存寄存器。当过程P调用Q时,Q可以覆盖这些寄存器,而不会破任何P所需要的数据。另一方面,寄存器%ebx、%esi和%edi被划分为被调用者保存寄存器。这意味着Q必须在覆盖这些寄存器之前,先把它们保存到栈中,并在返回前恢复它们。
过程示例
1 | int swap_add(int *xp, int *yp) |
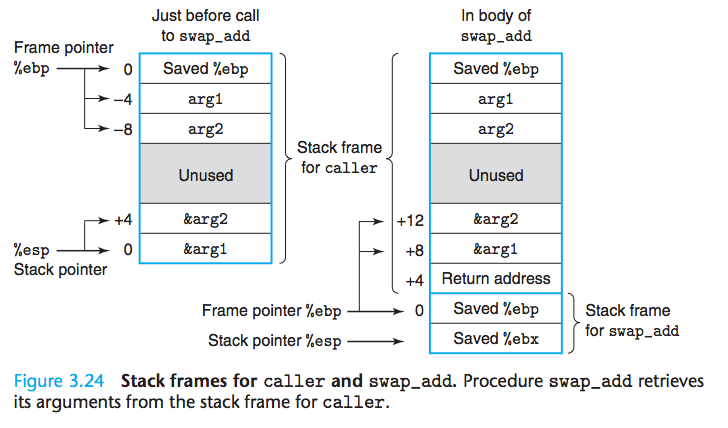
1
2
3
4
5
6
7
8
9
10
11
12caller:
pushl %ebp #save old %ebp, 保存上一个帧的开始地址
movl %esp, %ebp #set %ebp as frame pointer,更新%ebp地址为当前帧的地址
subl $24, %esp #alllocate 24 bytes on stack, 申请栈空间,指针头向下移动
movl $534, -4(%ebp) #set arg1 to 534
movl $1057, -8(%ebp) #set arg2 to 1057
leal -8(%ebp), %eax #compute &arg2
movl %eax, 4(%esp) #store on stack
leal -4(%ebp), %eax #compute &arg1
movl %eax, (%esp) #store to stack
call swap_add #call the swap_add function
ps:为什么GCC分配从不使用的空间
GCC为caller分配了24个字节,但是却只是用了16个字节,这是因为GCC坚持一个x86编程指导方针,也就是一个函数使用的所有栈空间必须是16字节的整数倍。包括%ebp值的4个字节和返回值的4个字节,caller一共使用了32个字节。采用这个规则是为了保证访问数据的严格对齐(alignment)。
swap_add开始代码:1
2
3
4swap_add:
pushl %ebp
movl %esp, %ebp
pushl %ebx #需要寄存器%ebp做为临时存储。因为这是一个被调用者保存的寄存器。
swap_add主体代码:1
2
3
4
5
6
7movl 8(%ebp), %edx #get xp
movl 12(%ebp), %ecx #get yp
movl (%edx), %ebx #get x
movl (%ecx), %eax #get y
movl %eax, (%edx) #store y at xp
movl %ebx, (%ecx) #store x at yp
addl %ebx, %eax #return value = x+y
这段代码从caller的栈帧中取出它的参数,这点需要注意。
swap_add结束代码:1
2
3popl %ebx #restore %ebx, 从栈帧中弹出之前存储的%ebx的值到%ebx,恢复%ebx的值
popl %ebp #restore %ebp, 从栈帧中弹出之前存储的%ebp的值到%ebp,恢复%ebp的值
ret #return, 弹出地址到%eip, 并且从上个帧调用call下一行的地址开始执行。
递归过程
上面描述的栈链接惯例使得过程能够递归地调用它们自身。因为每个调用过程都有它自己的私有空间,多个未完成调用的局部变量不会相互影响。
递归的阶乘程序的C代码:
1
2
3
4
5
6
7
8
9int rfact(int n)
{
int result;
if (n <= 1)
result = 1;
else
result = n * rfact(n-1);
return result;
}对应的汇编代码
1 | # argument: n at %ebp + 8 |
当n=1时,调用L53,被调用过程返回,然后继续执行imull指令 %eax 值 1
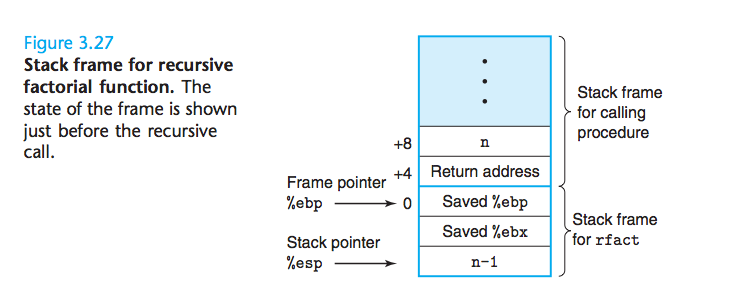
递归的阶乘函数的栈帧,这是递归调用之前的帧状态。
数组分配和访问
C语言中数组是一种将标量数据聚集成为更大数据类型的方式。
基本原则
对于数据类型T和整型常数N,声明如下:
T A[N]
它有两个效果:
- 它在存储器中分配一个\( L \bullet N \)字节的连续区域;这里L是数据类型T的大小(单位为字节), 用 \( x_{A} \) 来表示起始位置。
- 它引入了标符A;可以用A作为指向数组开头的指针,这个指针的值就是 \(x_{A}\) 。数组元素i被存放在地址为 \(x_{A} + L \bullet i\)的地方。
通过例子加深理解:1
2
3
4char A[12];
char *B[8]; //指针数组,数组的值是(char *)类型,指针的地址是int型的。
double C[6];
double *D[5];
| 数组 | 元素大小 | 总的大小 | 起始地址 | 元素i |
|---|---|---|---|---|
| A | 1 | 12 | \(x_{A}\) | \(x_{A} + i\) |
| B | 4 | 32 | \(x_{B}\) | \(x_{B} + 4i\) |
| C | 8 | 48 | \(x_{C}\) | \(x_{C} + 8i\) |
| D | 4 | 20 | \(x_{D}\) | \(x_{D} + 4i\) |
异质的数据结构
C语言提供了两种结合不同类型的对象来创建数据类型的机制:结构(structure),用关键字struct声明, 将多个对象集合到一个单位中;联合(union), 用关键字union声明,允许用集中不同的类型来引用一个对象。
数据对齐
许多计算机系统对基本数据类型合法地址做出了一些限制,要求某种类型对象的地址必须是某个值k(通常是2,4或8)的倍数。这种对齐限制简化了形成处理器和存储器系统之间接口的硬件设计。
例如:1
2
3
4
5struct S1 {
int i;
char c;
int j;
};
按照最小字节分配应该是这样的: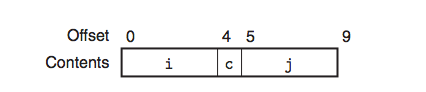
但是要遵循字节对齐,真实的分配情况是这样的:
综合:理解指针
指针和它们映射到机器代码的关键原则:
- 每个指针都对应一个类型。void * 类型代表通用指针。
- 每个指针都有一个值。这个值是某个指定类型对象的地址。
- 指针用&运算符创建。常用
leal指令来计算表达式的值。int * p = &x - 操作符用于指针的间接引用。
- 数组与指针紧密联系。
- 将指针从一种类型强制转换为另一种类型,只改变它的类型,而不改变它的值。
- 指针也可以指向函数。
存储器的越界引用和缓冲区溢出
C对于数组引用不进行任何边界检查,而且局部变量和状态信息(例如保存的寄存器值和返回地址),都存放在栈中。这两种情况结合到一起就可能导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。一种常见的状态破坏称为缓冲区溢出(buffer overflow)。入下图所示: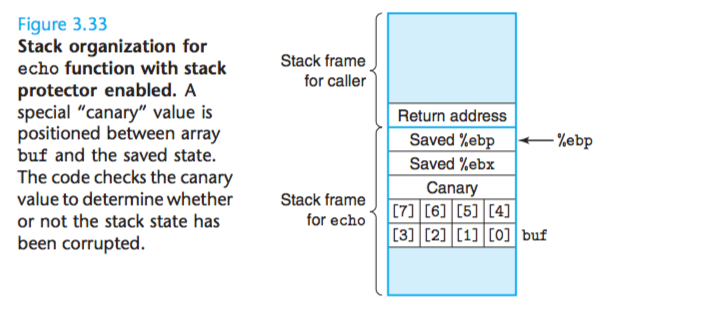
为buf分配的空间只有8个字节元素,上面地址保存的是%ebx, %ebp和返回地址的值,如果buf的长度超过分配的长度,就会把多出来的元素写入到保存这些寄存器地址的值,破坏%ebx,%ebp和返回地址的值,这样程序就不能正确的返回%ebx的值,不能正确的返回上以栈帧的地址,不能正确返回下一条要执行的命令地址。如果这些输入的元素包含一些可执行代码的字节编码,称为攻击代码(exploit code), 比如串改返回地址的值,使程序返回到恶意程序的代码地址进行执行,就会成为我们所说的蠕虫和病毒。
对抗缓冲区溢出攻击的方法:(详细的原理不再赘述,可以自己google)
- 栈随机化。
- 栈破坏检测。
- 限制可执行代码区域。