现代微处理器是人类创造的最复杂的系统之一。本章简要接受处理器硬件的设计。
一个处理器支持的指令和指令的字节级编码称为它的指令集体系结构(Instruction-Set Architecture, ISA)
Y86指令集体系结构
Y86指令就是它规定的一些指令的叫法和功能。指令编码就是这些指令的字节级编码。每条指令的第一个字节表明指令的类型,分为两部分,高4位是代码(code)部分,低4位是功能(function)部分。需要操作数的指令编码更长一些,例如rmmovl %esp, 0x12345(%edx)的字节编码40*42*45230100(注意是16进制, 每一位代表4个bit位),因为rmmovl第一个字节位40; 第二个字节应该是rArB(r代表源的类型,r:寄存器,m:存储器, 这里r是寄存器;A\B代表目的类型),%esp对应的数字为4,%edx对应的数字为2,所以第二个字节是:42;,最后4字节是偏移量0x12345的编码,首先补0填充为4字节:00 01 23 45, 然后反序插入:45230100。最后连起来就是404245230100。
Y86的顺序实现
将处理组织成阶段
将处理组织成阶段主要:
- 取指(fetch):取指阶段从存储器读取指令字节,地址为程序计数器(PC)的值。它按顺序方式计算当前指令的下一条指令的地址valP(等于PC的值加上已取出指令的长度)。
- 译码(decode):译码阶段从寄存器文件读入最多两个操作数, 得到值valA或/和valB。
- 执行(excute):执行阶段,算术/逻辑单元要么执行指令指明的操作,计算存储器引用的有效地址,要么增加或减少栈指针。
- 访存(memory):访存阶段可以将数据写入存储器,或者从存储器读出数据。
- 写回(write back):写回阶段最多可以写两个结果到寄存器文件。
- 更新PC(PC update):将PC设置成下一条指令的地址。
例如:
| 阶段 | OPl rA, rB |
|---|---|
| 取指 | icode:ifun<-\(M_{1}\)[PC] |
| rA:rB<-\(M_{1}\)[PC+1] | |
| valP<-PC+2 | |
| 译码 | valA<-R[rA] |
| valB<-R[rB] | |
| 执行 | valE<-valB OP valA |
| Set CC | |
| 访存 | |
| 写回 | R[rB]<-valE |
| 更新PC | PC<-valP |
SEO硬件结构
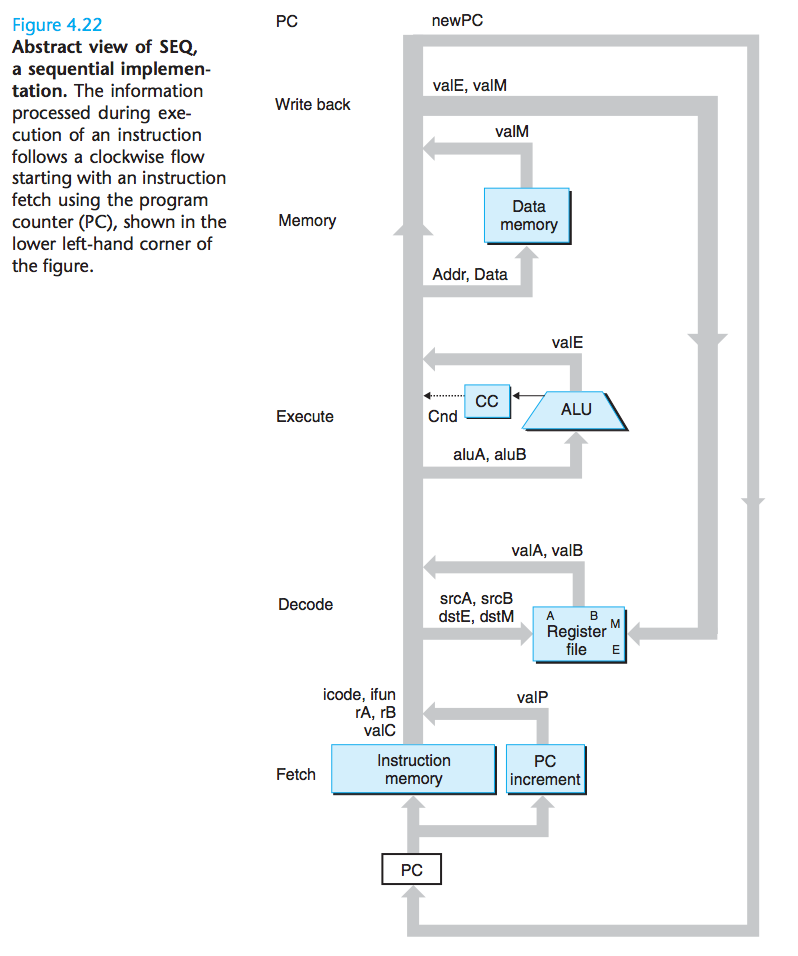
硬件单元与各个处理阶段的关联:
- 取指:将程序计数器寄存器作为地址,指令存储器读取指令的字节。PC增加器(PC incrementer)计算valP,即增加了的程序计数器。
- 译码:寄存器文件有两个读端口A和B,从这两个端口同事图去寄存器值valA和valB。
- 执行:根据指令的类型,将算术/逻辑单元(ALU)用于不同的目的。
- 访存:在执行访存操作时,数据存储器读出或写入一个存储器字。
- 写回:寄存器文件有两个写端口。端口E用来写ALU计算出来的值,而端口M用来写从数据存储器中读出的值。
SEO的时序
SEO的实现包括组合逻辑和两种存储器设备:时钟寄存器(程序计数器和条件码寄存器), 随机访问存储器(寄存器文件、指令存储器和数据存储器)。组合逻辑不需要任何时序或控制——只要输入变化了,值就通过逻辑门网络传播。现在有四个硬件单元需要对它们的时序进行明确的控制——程序计数器、条件码寄存器、数据存储器和寄存器文件。这些单元通过一个时钟信号来控制,它触发将新值转载到寄存器以及将值写到随机访问存储器。每个时钟周期,程序计数器都会装载新的指令地址。只有在执行整数运算指令时,才会装载条件码寄存器。只有在执行rmmovl, pushl或call指令时,才会写数据存储器。根据下图来理解处理器活动的时序控制: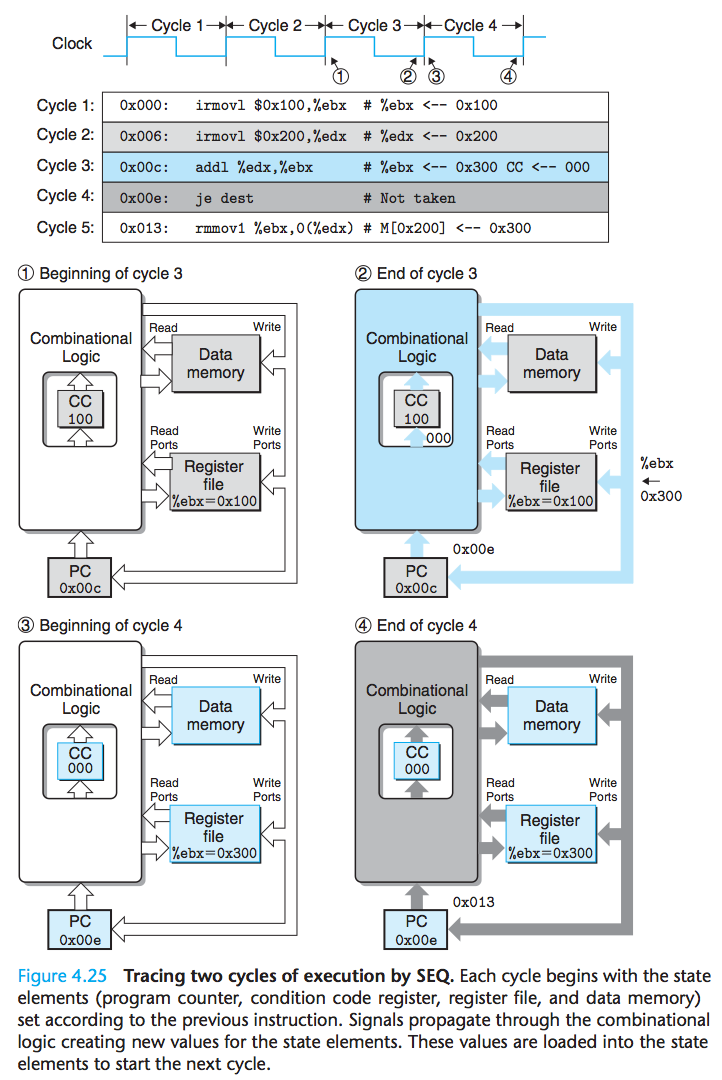
可以看出,其实所有的状态更新实际上同时发生,且只在时钟上升开始下一个周期时,保证这个等价性的原则是:处理器从来不需要为了完成一条指令的执行而去读由该指令更新了的状态,我对这句话的理解是,一个周期内(其实一个周期就是一条指令的执行)执行的指令所更新的数据不会成为该指令读取的数据。
上图中周期3通过组合逻辑算出了条件码的新值:000, %ebx的新值,以及程序计数器的新值(0x00e),但是这些都是一个临时状态,是组合逻辑的出口值,在下一个周期开始的时候,也就是电瓶上升沿,把这些临时的值更新到了xian相应的寄存器中,开始下一个逻辑运算。
SEO阶段的实现,就是以上每条指令逻辑运算的过程。不再说明。
流水线的通用原理
流水线化的一个重要特性就是增加了系统的吞吐量(throughput)。我理解吞吐量就是在单位时间内能够执行的命令个数。通过例子来说明:
非流水线化的计算硬件: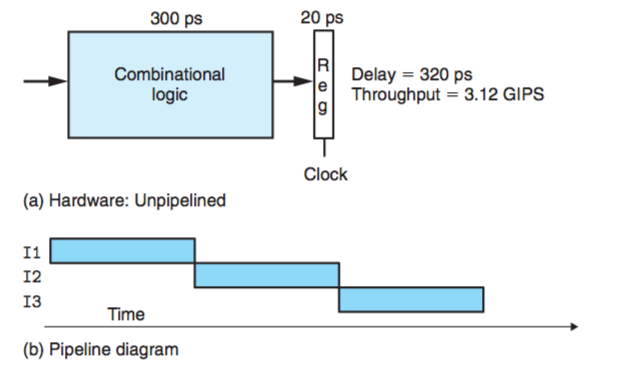
图中,I1,I2,I3表示的是三条指令。
一个组合逻辑需要300ps时间来进行运算,然后需要20ps的时间把数据加载到寄存器中,也就是一个延迟(latency)为320ps,所以可以计算处吞吐量:
\(吞吐量=\frac{1}{(300+20)*10^{-12}} \approx 3.12GIPS\)
流水线化的计算硬件: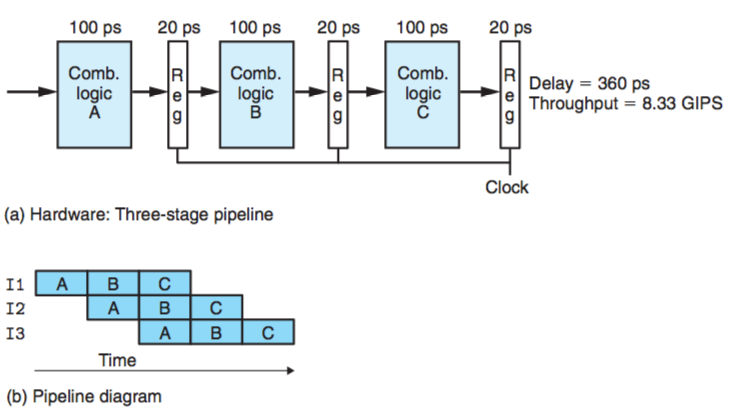
图中,I1,I2,I3表示的是三条指令, A, B, C表示执行每条指令需要三个阶段。这里每个阶段为100ps, 也就是把300ps分成三次来执行。但是各个阶段之间需要放上流水线寄存器(pipeline registers),每次加载寄存器都需要20ps, 所以可以看出执行一条指令需要3*(20+100)=360ps, 比之前执行一条指令多出来40ps。但是看一下流水线的流程,A先执行I 1指令,执行完后,B开始执行I1指令,这时I2就可以进入A阶段进行执行了,最终的结果是A, B, C都在自行命令。也就是得到流水线的吞吐量是:
\(吞吐量=\frac{1}{(100+20)*10^{-12}} \approx 8.33GIPS\)
对于这三条指令可以看出,非流水线状态下一共执行了960ps, 流水线情况下执行了600ps, 提高了整个系统的执行效率。
ps: 不是流水线的级数越多约好,因为级数增加的,每个阶段的执行时间减少,吞吐量增加了,但是整个执行过程的延迟也增加了,所以收益不一定会变好。所以实际过程中要兼顾吞吐量和时延两个指标。
后面的内容说的是具体流水线的设计实现,这里就不再说了。