apache工作原理
apache httpd通过模块化的设计来适应各种环境,模块化的使用使其变得功能强大而且灵活。最基本的web服务器功能也是通过可选择的多处理模块(MPM),用来绑定到网络端口上,以及调度子程序处理请求。这样做可以带来两个重要的好处:
- Apache httpd 能更优雅,更高效率的支持不同的平台。尤其是 Apache httpd 的 Windows 版本现在更有效率了,因为 mpm_winnt 能使用原生网络特性取代在 Apache httpd 1.3 中使用的 POSIX 层。它也可以扩展到其它平台 来使用专用的 MPM。
- Apache httpd 能更好的为有特殊要求的站点定制。例如,要求 更高伸缩性的站点可以选择使用线程的 MPM,即 worker 或 event; 需要可靠性或者与旧软件兼容的站点可以使用 prefork。
下面主要介绍常用的两个MPM工作原理。
perfork
一个单独的控制进程(父进程)负责产生子进程,这些子进程用于监听请求并作出应答。Apache总是试图保持一些备用的 (spare)或是空闲的子进程用于迎接即将到来的请求。这样客户端就无需在得到服务前等候子进程的产生。在Unix系统中,父进程通常以root身份运行以便邦定80端口(注意这里是先绑定再fork的,所以意味着所有的子进程都监听了80端口),而 Apache产生的子进程通常以一个低特权的用户运行。User和Group指令用于配置子进程的低特权用户。运行子进程的用户必须要对他所服务的内容有读取的权限,但是对服务内容之外的其他资源必须拥有尽可能少的权限。
子进程的个数会随着请求量的大小动态调整。调整的策略与perfork的配置息息相关,httpd.conf的配置文件有以下配置:1
2
3
4
5
6
7<IfModule prefork.c>
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxClients 150
MaxRequestsPerChild 0
</IfModule>
具体的流程这里直接copyApache运行机制剖析这篇博文的介绍。
- 控制进程先建立’StartServers’个子进程;
- 当空闲进程数小于MinSpareServers时,继续创建子进程,直到满足空闲进程数大于等于MinSpareServers;
- 当并发请求高时而空闲进程数小于MinSpareServers时会继续创建子进程,最多可以创建MaxClients个;
- 当并发高峰过去时,空闲进程的数量大于MaxSpareServers时会删除多余的子进程,直到剩MaxSpareServers为止;
- 当子进程处理的连接数超过MaxRequestsPerChild时,自动关闭,当MaxRequestsPerChild为0时这没有这个限制;
对每个参数的介绍如下:
StartServers指定服务器启动时建立的子进程数量。MinSpareServers最小的空闲进程数。如果当前空闲进程数少于MinSpareServers时,Apache将以每秒一个的速度产生新的子进程。MaxSpareServers最大的空闲进程数。如果空闲进程数大于这个值,Apache父进程会自动kill掉一些多余的子进程。MaxRequestsPerChild每个子进程可处理的请求数。每个子进程处理完MaxRequestsPerChild后将自动销毁。0意味着用户销毁。销毁的好处有以下两个:- 可以防止意外的内存泄露
- 在服务器负载下降的时候会自动减少子进程数
MaxClients设定Apache可以同时处理的请求,是对性能影响最大的参数。如果请求数达到这个限制,那么后来的请求就需要排队,直到某个请求处理完毕。
worker
每个进程能够拥有的线程数量是固定的。服务器会根据负载情况增加或减少进程数量。一个单独的控制进程(父进程)负责子进程的建立。每个子进程能够建立ThreadsPerChild数量的服务线程和一个监听线程,该监听线程监听接入请求并将其传递给服务线程处理和应答。Apache总是试图维持一个备用(spare)或是空闲的服务线程池。这样,客户端无须等待新线程或新进程的建立即可得到处理。在Unix中,为了能够绑定80端口,父进程一般都是以root身份启动,随后,Apache以较低权限的用户建立子进程和线程。User和Group指令用于配置Apache子进程的权限。虽然子进程必须对其提供的内容拥有读权限,但应该尽可能给予他较少的特权。另外,除非使用了suexec ,否则,这些指令配置的权限将被CGI脚本所继承。
相对于prefork,worker是2.0 版中全新的支持多线程和多进程混合模型的MPM。由于使用线程来处理,所以可以处理相对海量的请求,而系统资源的开销要小于基于进程的服务器。但是,worker也使用了多进程,每个进程又生成多个线程,以获得基于进程服务器的稳定性。这种MPM的工作方式将是Apache 2.0的发展趋势。
http.conf中也有关于worker的配置项:1
2
3
4
5
6
7
8
9
10<IfModule worker.c>
StartServers 3
MaxClients 2000
ServerLimit 25
MinSpareThreads 50
MaxSpareThreads 200
ThreadLimit 200
ThreadsPerChild 100
MaxRequestsPerChild 0
</IfModule>
由主控制进程生成“StartServers”个子进程,每个子进程中包含固定的ThreadsPerChild线程数,各个线程独立地处理请求。同样,为了不在请求到来时再生成线程,MinSpareThreads和MaxSpareThreads设置了最少和最多的空闲线程数;而MaxClients设置了所有子进程中的线程总数。如果现有子进程中的线程总数不能满足负载,控制进程将派生新的子进程。
参数介绍:StartServer 服务器启动时建立的子进程数。ServerLimit 服务器允许配置的进程数上限。这个指令和ThreadLimit结合使用配置了MaxClients最大允许配置的数值。MinSpareThreads 最小空闲线程数。这个MPM将基于整个服务器监控空闲线程数。如果服务器中的总线程数太少,子进程将产生新的空闲线程。MaxSpareThreads 最大空闲线程数。这个MPM将基于整个服务器监控空闲线程数。如果服务器总的线程数太多,子进程将kill掉多余的空闲线程。MaxSpareThreads的取值范围是有限制的。ThreadLimit 每个子进程可配置的线程数上限。这个指令配置了每个子进程可配置的线程数ThreadsPerChild上限。ThreadsPerChild 每个子进程建立的常驻的执行线程数。子进程在启动时建立这些线程后就不再建立新的线程了。MaxRequestsPerChild 每个子进程在其生存期间允许执行的最大请求数量。到达这个限制后子进程将会结束,如果为0则永不结束( 注意,对于KeepAlive链接,只有第一个请求会被计数)。这样做的好处是:
- 能够防止内存泄露无限进行,从而耗尽内存。
- 給进程一个有限寿命,从而有助于当服务器负载减轻时减少活动进程的数量。
apache”惊群”现象与解决方案
无论是上面那个MPM被选择,都有一问题就是主进程先监听80端口,然后又fork出子进程。所以可以知道,fork出来的每个子进程都在监听80端口,如果这时候有请求过来就会出现所有的空闲进程都回来抢这个fd,也就是这些进程都被唤醒了,但是最终只有一个进程能够拿到这个fd进行处理,其他进程因为拿不到进程而再次进入休眠状态,这就是”惊群”现象。
apache的prefork模型下的处理方式如下如所示:
apache通过在每个accept()函数上 增加互斥锁和条件变量 来解决这个惊群问题。保证每个请求只会被一个线程刚好拿到,不会影响其他线程;
这里详细介绍下:条件变量与互斥锁不同,条件变量是用来等待而不是用来上锁的。条件变量用来自动阻塞一个线程,直到某特殊情况发生为止。通常条件变量和互斥锁同时使用;互斥锁提供互斥机制,条件变量提供信号机制;
那么apache是如何利用条件变量和互斥锁来解决每次只有一个空闲线程被唤醒,并且处于监听者角色呢?
每次一个新的客户请求过来,正在监听的线程与该请求建立连接,并变为worker工作者线程。让出监听者角色时它同时发送信号到条件变量,并释放锁。这样在空闲(idle)状态的一个线程将被唤醒并获得锁。
也就是说:条件变量保证了其他线程在等待条件变化期间处于睡眠;互斥锁保证一次只有一个线程被唤醒
这个是参考客户/服务器程序设计范式来的,但是有一个明显的问题是prefork是多进程模型不是多线程模型,由于现在还没读过apache源码,姑且认为总体的流程和思想是对的。有机会再深入阅读回来补充。
nginx工作原理
nginx使用的是多进程模型,类似于apache的prefork,不同的是nginx的子进程个数是固定的。nginx的进程模型可以用下图来表示: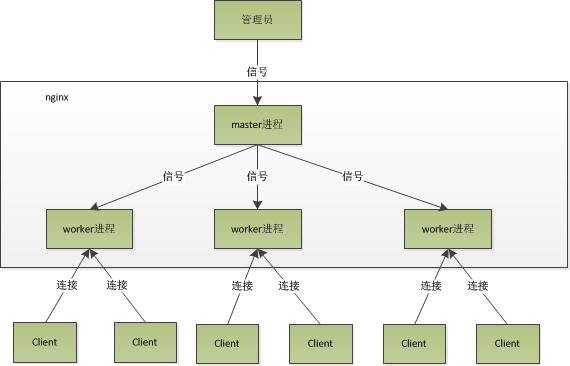
可以看到nginx进程模型是由一个mater进程和多个worker进程组成的,master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。 worker进程则是来处理请求用的。
异步非阻塞
上面提到nginx的worker进程用来处理请求,而worker的个数是有限的,当并发高的时候nginx是如何应对的呢?这里不得不提到一个概念异步非阻塞(参考UNP卷一第三版P160页的介绍)关于这个过程nginx平台初探介绍的很好,直接COPY过来:
为什么nginx可以采用异步非阻塞的方式来处理呢,或者异步非阻塞到底是怎么回事呢?我们先回到原点,看看一个请求的完整过程。首先,请求过来,要建立连接,然后再接收数据,接收数据后,再发送数据。具体到系统底层,就是读写事件,而当读写事件没有准备好时,必然不可操作,如果不用非阻塞的方式来调用,那就得阻塞调用了,事件没有准备好,那就只能等了,等事件准备好了,你再继续吧。阻塞调用会进入内核等待,cpu就会让出去给别人用了,对单线程的worker来说,显然不合适,当网络事件越多时,大家都在等待呢,cpu空闲下来没人用,cpu利用率自然上不去了,更别谈高并发了。好吧,你说加进程数,这跟apache的线程模型有什么区别,注意,别增加无谓的上下文切换。所以,在nginx里面,最忌讳阻塞的系统调用了。不要阻塞,那就非阻塞喽。非阻塞就是,事件没有准备好,马上返回EAGAIN,告诉你,事件还没准备好呢,你慌什么,过会再来吧。好吧,你过一会,再来检查一下事件,直到事件准备好了为止,在这期间,你就可以先去做其它事情,然后再来看看事件好了没。虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的。所以,才会有了异步非阻塞的事件处理机制,具体到系统调用就是像select/poll/epoll/kqueue这样的系统调用。它们提供了一种机制,让你可以同时监控多个事件,调用他们是阻塞的,但可以设置超时时间,在超时时间之内,如果有事件准备好了,就返回。这种机制正好解决了我们上面的两个问题,拿epoll为例(在后面的例子中,我们多以epoll为例子,以代表这一类函数),当事件没准备好时,放到epoll里面,事件准备好了,我们就去读写,当读写返回EAGAIN时,我们将它再次加入到epoll里面。这样,只要有事件准备好了,我们就去处理它,只有当所有事件都没准备好时,才在epoll里面等着。这样,我们就可以并发处理大量的并发了,当然,这里的并发请求,是指未处理完的请求,线程只有一个,所以同时能处理的请求当然只有一个了,只是在请求间进行不断地切换而已,切换也是因为异步事件未准备好,而主动让出的。这里的切换是没有任何代价,你可以理解为循环处理多个准备好的事件,事实上就是这样的。与多线程相比,这种事件处理方式是有很大的优势的,不需要创建线程,每个请求占用的内存也很少,没有上下文切换,事件处理非常的轻量级。并发数再多也不会导致无谓的资源浪费(上下文切换)。更多的并发数,只是会占用更多的内存而已。 我之前有对连接数进行过测试,在24G内存的机器上,处理的并发请求数达到过200万。现在的网络服务器基本都采用这种方式,这也是nginx性能高效的主要原因。
所以推荐设置worker的个数为cpu的核数,在这里就很容易理解了,更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,提供了cpu亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效。
nginx”惊群”现象与解决方案
worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
因为这里主要是对比apache与nginx的原理的不同,所以更深入的探讨nginx这里先不做介绍更深入的探讨nginx这里先不做介绍,以后有机会学习nginx源码的时候再写。
参考文献
多处理模块(MPM)
Apache运行机制剖析
nginx平台初探
客户/服务器程序设计范式
“惊群”,看看nginx是怎么解决它的
web服务器nginx和apache的对比分析