前言
这个系列的文章主要是帮助你理解指针,栈,堆,逃逸分析和值/指针语义的设计和机制。本系列一共有四篇,这是第一篇。本篇主要是介绍栈和指针。
本系列文章索引:
1) Go 语言机制之栈和指针
2) Go 语言机制之逃逸分析
3) Go 语言机制之内存性能分析
4) Go 语言机制之数据和语义的使用原则
简介
我并不打算美化指针,因为指针真的很难理解。如果我们使用不当,指针能够产生很难理解的 bug 甚至影响性能。 在写并发程序或者多线程程序时这种问题更为明显。这也难怪很多语言试图对开发者隐藏指针的使用。尽管如此,如果你是用 Go 来开发程序,你是没有办法避免使用指针的。相对于深入的理解指针,你更应该关注如何写出干净,简单并且有效的代码。
帧边界
帧边界为每个函数提供了独立的内存空间的,这些函数都运行在自己的内存空间中。每个帧都允许他自己的函数操作他的上下文并且能够提供流程控制。一个函数可以通过帧指针直接访问它所在帧的内存,但如果要访问帧外的内存就需要间接访问。为了能够让函数访问所在帧外的内存, 这个内存需要在函数之间共享。帧边界之间的这种限制和原则是需要首先明白的。
当一个函数被调用时在两个帧之间就会出现上下文切换。代码会从调用的函数所在的帧切换到被调用函数所在的帧。如果函数调用需要传递数据,这个数据必须要从一个帧传输到另一个帧。两个帧之间的数据传递在 Go 中是通过”值传递”来完成的。
通过”值传递”来传输数据的优点是可读性好。你说看到的值就是函数调用被复制和接收到的值。这就是我为什么说”值传递”是 WYSIWYG(what you see is what you get),所见即所得。所有这些都使你在编写两个函数 调用时不会隐藏上下文切换的成本。”值传递”会帮助你很好的理解当函数调用时所产生的影响。
下面这段代码就是函数通过”值传递”来传输整形数据的例子:
list 1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
// Pass the "value of" the count.
increment(count)
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc int) {
// Increment the "value of" inc.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
}
当你的程序启动的时候, runtime 就会创建 main goroutine 开始初始化main 函数中的代码。一个 goroutine 就是存在于操作系统线程( 最终会运行在一些核上)的一个执行路径。Go 1.8版本以后每个 goroutine 回初始化2048字节(byte)的栈空间。这个初始化栈空间在过去几年发生过几次变化了, 未来也可能会再次修改。
栈非常重要,因为它为每个独立的函数提供了祯边界之间的物理内存空间。当 list 1 的 main 函数执行的时候,goroutine 的栈空间如下图所示:
Figure 1: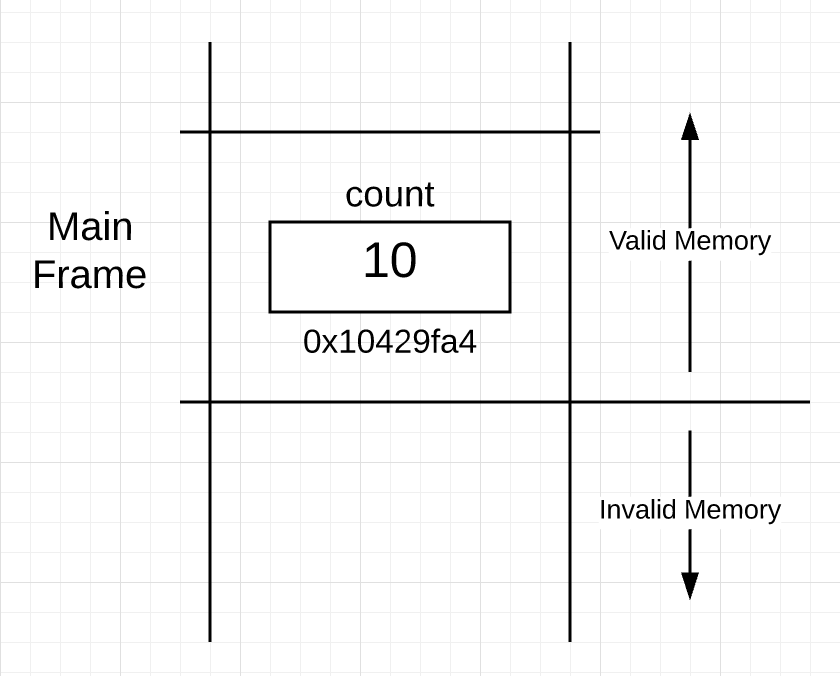
在 Figure 1 中你可以看到,main函数对应的栈已经被创建出来了。 这块儿空间被成为『栈帧』, 这个框表示的是main函数的堆边界。当函数被调用的时候,这个帧是正在执行的代码的一部分。可以看到变量count被放到了main函数的帧中地址为0x10429fa4 的地方。
Figure 1 同样也表明了一个非常有趣的点。 当前活动的帧下面所有堆内存都是不可用的,但是从这个帧开始上面的地址是可用的。我需要清晰的知道堆中可用和不可用的部分的边界。
地址
变量的目的是为了给一个特定的内存地址进行命名,以便于提高程序的可读性,并且能够帮助你了解自己正在使用的数据。如果你有一个变量的话你就必须在内存中有一个变量值,如果你有一个变量值你就必须有一个内存地址。在line 9, main函数调用一个内置的函数println来输出变量count的值和地址
Listing 2
1 | println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]") |
使用符号&来获取变量的地址已经不陌生了,很多语言也是这样使用的。如果你在32bit的机器上运行这段代码的话,第9行代码的输出与下面的形式很相似:
listing 31
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
函数调用
在12行代码, main函数调用了increment函数:
Listing 41
increment(count)
函数调用意味着goroutine需要在内存栈中申请一段新的内存。然而,事情比较复杂。为了能够成功的调用这个函数,数据需要突破帧边界放到新的帧中。举个例子就是整型数据需要被复制并且在调用的过程中被传递。可以根据increment函数18行的函数定义看到。
Listing 51
func increment(inc int) {
如果再回来看12行代码increment函数的调用,可以看到代码传递的是变量count的值。这个值会被复制,然后放到increment函数所在的新帧中。需要记住一点,increment函数只能够直接读写他自己帧中的内存地址,所以它需要变量inc能接收,存储并且访问传递过来的count的副本。
在increment函数开始执行之前,goroutine栈的结构如下: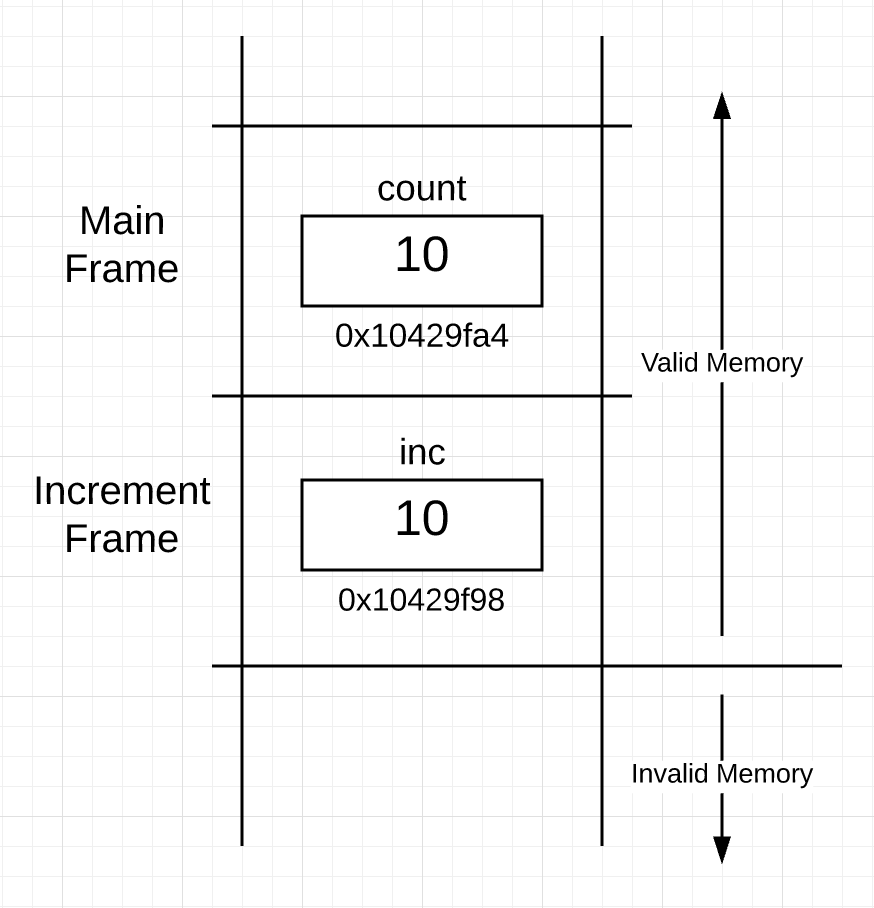
现在可以看到栈中有两个帧,一个是main函数的,在它下面是increment函数的。在increment函数的帧中,可以看到变量inc的值是10,这个值是在函数调用的时候复制并传递过来的。变量inc的地址是0x10429f98, 这个地址在内存中比较低,是因为栈是向增长的, 这是内部实现的一个细节,这里不需要关注。重要的是toroutine把main函数中的变量count的值得副本传递到了函数increment中的变量inc。
函数increment剩下的代码就是打印出变量inc的值和地址。
Listing 61
2inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
第12行代码的输出与下面的形式很相似:
Listing 71
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
执行完函数调用后,内存中栈的结构如下:
Figure 3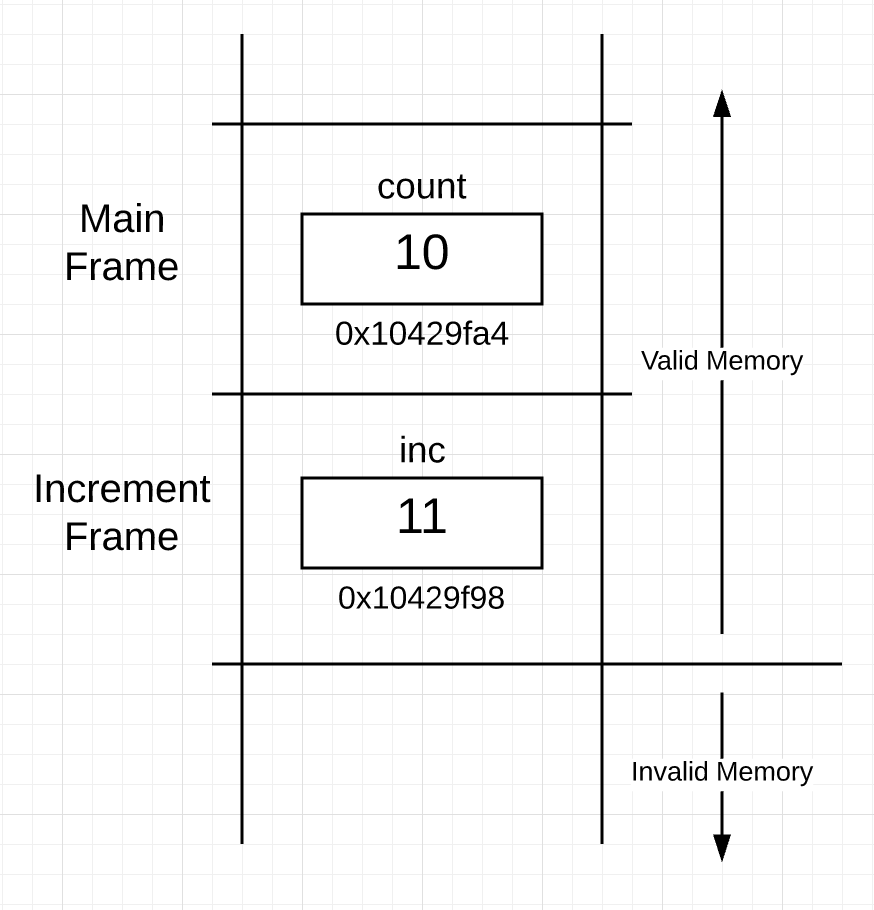
21行和22行代码执行完后函数increment就把控制权交回给了main函数。然后main函数在14行打印出了变量count的值和地址。
Listing 81
println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")
这个函数完整的输出入下:
Listing 91
2
3count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
在函数increment函数调用前和调用后,变量count的值在main函数所在的帧中值是一样的。
函数返回值
在内存栈中当被调用的函数把控制权返还给调用函数的时候到底发生了什么?一句话来回答就是:什么也没发生。下面就是当increment函数返回后栈的结构:
Figure 4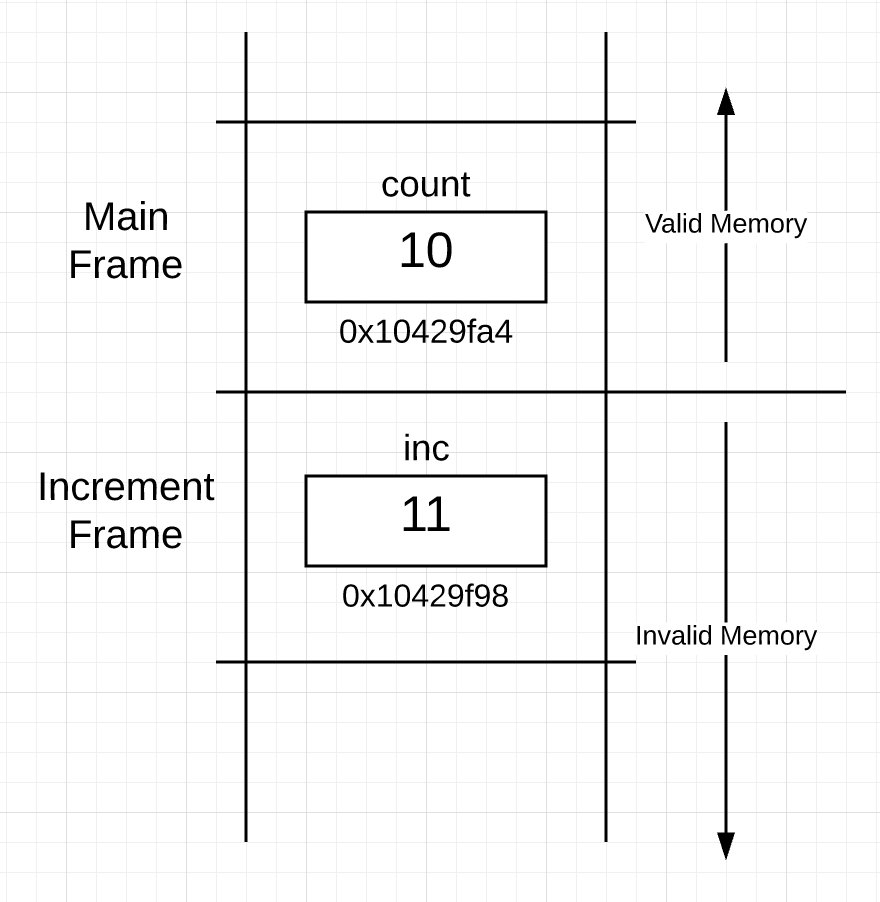
这个栈结构和Figure 3的结构一模一样,唯一的区别就是函数increment所在的帧现在是无法访问的内存了。因为现在main函数是工作的帧, 为函数increment创建的帧是无法访问的。
为被调用的函数返回后帧所占用的内存进行清除是一个比较费时间的,因为你不知道这些内存是否会被再次用到。所以当函数调用时这些帧需要被再次用到时帧所占用的内存才会被清除,否则就会放在那不管。
通常在每次函数调用中,栈都会进行清除,一般都是在帧中进行变量初始化的时候完成的,因为每个变量都会被初始化,即使是使用默认值, 初始化的时候就需要占用内存。
共享值
如果我们想让函数increment直接操作main函数中的变量count该怎么做呢?这时候就需要指针了。指针存在的目的就是为了让函数共享一个值以便能够读写变量的值, 及时这个值不在它自己的帧中。
如果你不需要共享,那就不需要用到指针。学习指针的时候重要的是清晰的词汇而不是语法或者操作符。所以记住指针是为了共享,读代码的时候不要用操作符&来代替共享的意思。