Go单元测试
在计算机编程中,单元测试(英语:Unit Testing)又称为模块测试,是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。
我们为何要进行单元测试呢?其实如果你不添加单元测试的话,别人调用你提供的函数是,其实就是帮你做测试,但是这种测试我们越早做越能发现问题.
单元测试的粒度
程序单元是应用的最小可测试部件。在过程化编程中,一个单元就是单个程序、函数、过程等;对于面向对象编程,最小单元就是方法,包括基类(超类)、抽象类、或者派生类(子类)中的方法。在 Go 中程序单元指的是Package中的方法。
那么我们对于 Go 中改对那些函数写单元测试呢?这里的答案是: 包中可导出的函数。 因为这些函数是对外可见的,这些是我们包的入口。那么对于不可导出的函数我们是否需要些单元测试呢?答案是不用。有些人可能会有一位,如果我们不对不可导出的函数写单元测试,那么如何保证单元测试的覆盖率呢?因为有些不可导出函数的覆盖率达不到要求。这里要说的是: 如果有些不可导出函数单元测试覆盖率达不到,有两点可能性:
- 这些逻辑是不需要的,你可以直接去掉
- 你的测试用例不够,你需要增加可导出函数的测试用例
单测的三个原则
还有一个问题是: 我该先开发功能在写单元测试,还是先写单元测试再开发功能?
其实关于TDD有三个定律:
- You are not allowed to write any production code unless it is to make a failing unit test pass.
- You are not allowed to write any more of a unit test than is sufficient to fail; and compilation failures are failures.
- You are not allowed to write any more production code than is sufficient to pass the one failing unit test.
关于这三条定律,我发现每个人翻译的都不一样,我觉得比较符合我的理解的翻译是:
- 除非是为了使一个失败的 unit test 通过,否则不允许编写任何产品代码
- 在一个单元测试中,只允许编写刚好能够导致失败的内容(编译错误也算失败)
- 只允许编写刚好能够使一个失败的 unit test 通过的产品代码
如果违反了会怎么样呢?
违反第一条,先编写了产品代码,那这段代码是为了实现什么需求呢?怎么确保它真的实现了呢?
违反第二条,写了多个失败的测试,如果测试长时间不能通过,会增加开发者的压力,另外,测试可能会被重构,这时会增加测试的修改成本。
违反第三条,产品代码实现了超出当前测试的功能,那么这部分代码就没有测试的保护,不知道是否正确,需要手工测试。可能这是不存在的需求,那就凭空增加了代码的复杂性。如果是存在的需求,那后面的测试写出来就会直接通过,破坏了 TDD 的节奏感。
还是针对上面的问题: 先写单元测试还是先写功能?
我的答案是: 单元测试-> 功能开发 -> 单元测试 -> 功能开发…
它们应该是交替进行的,既: 先写小范围的单元测试,然后针对这些测试进行开发功能,等所有测试通过后继续增加测试case, 然后针对新增的case继续编写功能,直到功能满足了需求为止。
测试行为, 而非实现
Avoid Testing Implementation Details, Test Behaviours
当我们测试行为时,我们的意思是 : “我不在乎你是如何得出答案的,只要确保在这种情况下答案是正确的”
当我们测试实现时,我们的意思是 : “我不在乎答案是什么,只要确保它是按照你规定的方式工作的。”
初级
单元测试编写
下面给出一个完整的Go的单元测试的例子:split.go文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16package split
import "strings"
// Split slices s into all substrings separated by sep and
// returns a slice of the substrings between those separators.
func Split(s, sep string) []string {
var result []string
i := strings.Index(s, sep)
for i > -1 {
result = append(result, s[:i])
s = s[i+len(sep):]
i = strings.Index(s, sep)
}
return append(result, s)
}
split_test.go文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
got := Split("a/b/c", "/")
want := []string{"a", "b", "c"}
if !reflect.DeepEqual(want, got) {
t.Fatalf("expected: %v , got %v", want, got)
}
}
Go官方网站有关于单元测试的写法介绍, 以上面的代码为例:
一般我们需要单元测试文件和要测试的包的文件需要在同一个目录下,并且以
_test.go结尾。1
2
3src/split/
├── split.go
└── split_test.go单元测试的函数名为
Test+ 要测试的函数名。1
2
3
4// 要测试的函数
func Split(...)
// 单元测试函数
func TestSplit(...)单元测试函数的参数是固定的 (*testing.T):
1
func TestSplit(t *testing.T) {}
运行单元测试
Go语言的工具链中提供了很强大的单元测试工具:go test, 如果想要运行刚才的单元测试,我们只需要在split文件夹下执行:1
go test
就可以得出测试结果:1
2
3$go test
PASS
ok split 0.008s
运行多个单元测试
有是有我们需要同时运行多个单元测试, 如果这些单元测试在同一个包下:1
2
3
4
5
6
7
8
9
10
11
12$GOROOT/src/encoding/xml/
├── atom_test.go
├── example_marshaling_test.go
├── example_test.go
├── example_text_marshaling_test.go
├── marshal.go
├── marshal_test.go
├── read.go
├── read_test.go
├── typeinfo.go
├── xml.go
└── xml_test.go
我们可以直接运行: go test
如果这些单元测试文件不在同一个包下:
1 | $GOROOT/src/encoding/ |
我们需要在这些包的外面运行: go test ./...
覆盖率测试
如果我们想要查看单元测试的覆盖率,Go 工具链也是支持的, 详情可以参考官方的Blog: The cover story
如果要查看单元测试覆盖率,我们可以运行:1
2
3
4$go test -cover
PASS
coverage: 100.0% of statements
ok split 0.013s
但是上面的测试只给出了覆盖率的值,并没有看到详细的信息,如果我们需要查看覆盖率的详细信息,可以把测试覆盖率的内容输出到文件中:1
$go test -coverprofile=coverage.out
这样,测试覆盖率的详细信息就输出到了文件coverage.out中。
如过要查看每个函数的测试覆盖率,可以利用刚才的coverage.out文件:1
2
3$go tool cover -func=coverage.out
split/split.go:7: Split 100.0%
total: (statements) 100.0%
如果要想可视化测试覆盖率,还可以生成html格式:1
$go tool cover -html=coverage.out
我们可以看到每行的覆盖情况: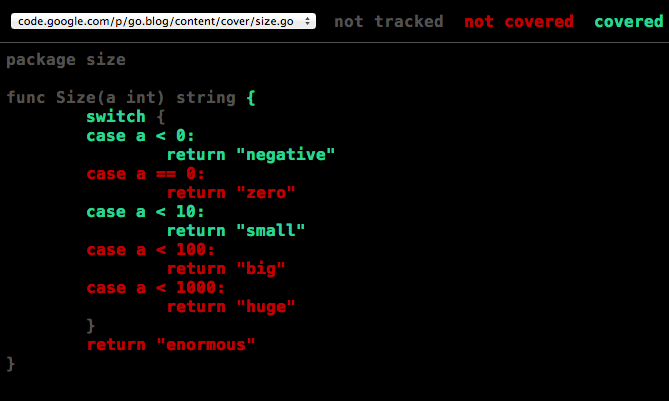
其中红色代表没有覆盖到,绿色代表覆盖到,灰色代表不计入测试覆盖率的范围
进阶
多个case
前面我们讲了如何进行基本的单元测试,但是现实中往往我们需要对同一个函数进行多个case的测试,那么其实有两种写法:
针对每个case写一个测试函数:
对于比较复杂的函数,其函数的表现可能会收到不同环境因素的影响,他们的单元测试写法差别也比较大,比如beego中 logs/file 的单元测试, 同样是测试FileDailyRotate函数,TestFileDailyRotate_01测试的是创建文件, TestFileDailyRotate_02测试的是当创建的文件存在时,给文件加后缀。
同一个测试函数里有多个case:
一般比较简单的单元测试,只是根据输入的不同而产生不同的输出,则可以使用这种方式。比如前面说的split函数的多个case测试, 我们把split_test.go改为下面的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
type test struct {
input string
sep string
want []string
}
tests := []test{
{input: "a/b/c", sep: "/", want: []string{"a", "b", "c"}},
{input: "a/b/c", sep: ",", want: []string{"a/b/c"}},
{input: "abc", sep: "/", want: []string{"abc"}},
}
for _, tc := range tests {
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(tc.want, got) {
t.Fatalf("expected: %v , got %v", tc.want, got)
}
}
}
边界条件测试
由长期的测试工作经验得知,大量的错误是发生在输入或输出的边界上。因此针对各种边界情况设计测试用例,可以查出更多的错误。上面的case中我们并没有对边界条件进行测试,下面我们加上一个边界条件的测试case:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
type test struct {
input string
sep string
want []string
}
tests := []test{
{input: "a/b/c", sep: "/", want: []string{"a", "b", "c"}},
{input: "a/b/c/", sep: "/", want: []string{"a", "b", "c"}},
{input: "a/b/c", sep: ",", want: []string{"a/b/c"}},
{input: "abc", sep: "/", want: []string{"abc"}},
}
for _, tc := range tests {
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(tc.want, got) {
t.Fatalf("expected: %v , got %v", tc.want, got)
}
}
}
然后我们执行单元测试:1
2
3
4
5
6
7$go test
=== RUN TestSplit
--- FAIL: TestSplit (0.00s)
split_test.go:25: expected: [a b c] , got [a b c ]
FAIL
exit status 1
FAIL split 0.015s
可以看到我们的单元测试有一个case没有通过,但是这里有一点疑问:哪个测试case没过?
定位测试case
通过编号定位
我们可以给每个case一个编号:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
type test struct {
input string
sep string
want []string
}
tests := []test{
{input: "a/b/c", sep: "/", want: []string{"a", "b", "c"}},
{input: "a/b/c/", sep: "/", want: []string{"a", "b", "c"}},
{input: "a/b/c", sep: ",", want: []string{"a/b/c"}},
{input: "abc", sep: "/", want: []string{"abc"}},
}
for i, tc := range tests {
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(tc.want, got) {
t.Fatalf("test %d: expected: %v , got %v", i+1, tc.want, got)
}
}
}
这时候执行
1 | $ go test |
这里可以定位出 test 2 有问题的,但是编号的问题是 :
- 每个人定义的开始下标可能不同: 有的人是从
0开始,有的人从1开始,照成理解不一致 - 随着case的增多,同样不好定位具体的
case: 如果你要从50个case中定位第27个case, 还是比较费时的。
通过名字定位
还有一种方式: 我们给每个case一个名字:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
type test struct {
name string
input string
sep string
want []string
}
tests := []test{
{name: "simple", input: "a/b/c", sep: "/", want: []string{"a", "b", "c"}},
{name: "trailing sep", input: "a/b/c/", sep: "/", want: []string{"a", "b", "c"}},
{name: "wrong sep", input: "a/b/c", sep: ",", want: []string{"a/b/c"}},
{name: "no sep", input: "abc", sep: "/", want: []string{"abc"}},
}
for _, tc := range tests {
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(tc.want, got) {
t.Fatalf("%s: expected: %v , got %v", tc.name, tc.want, got)
}
}
}
1 | $go test |
现在我们可以看到我们可以很好的通过trailing sep快速定位到了具体的case
随机测试case
上面的测试方式看上去很完美了,可以如果我们实现的时候没有注意,case之间可能会相互影响, 比如一个case在函数内部修改了一个全局变量,下一个case的执行就会受到这种影响。为了避免由于测试顺序带来的问题,我们一般都会让每个case之间的顺序是随机的,而不是按照特定的顺序,而slice本身有顺序的,所以不满足我们的条件,这时我们可以使用map, 同时还可以把name放到map的key中,简化我们的写法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
tests := map[string]struct {
input string
sep string
want []string
}{
"simple": {input: "a/b/c", sep: "/", want: []string{"a", "b", "c"}},
"trailing sep": {input: "a/b/c/", sep: "/", want: []string{"a", "b", "c"}},
"wrong sep": {input: "a/b/c", sep: ",", want: []string{"a/b/c"}},
"no sep": {input: "abc", sep: "/", want: []string{"abc"}},
}
for name, tc := range tests {
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(tc.want, got) {
t.Fatalf("%s: expected: %v , got %v", name, tc.want, got)
}
}
}
然后执行单元测试:1
2
3
4
5
6$go test
--- FAIL: TestSplit (0.00s)
split_test.go:23: trailing sep: expected: [a b c] , got [a b c ]
FAIL
exit status 1
FAIL split 0.014s
并发测试
看上去前面的测试更加完美了, 但是……
我们的测试case出现错误的时候,我们会调用:1
t.Fatalf("%s: expected: %v , got %v", name, tc.want, got)
打印我们的错误信息,但是这个错误信息打印后整个测试过程就结束了,如果我们有很多个case需要测试,而前面的case失败后就无法进行后面的测试了,这时候我们如果针对这个出错的case修改后,我们会发现其他的case有报错了,我们反复的修改,但是我们并不知道自己到底有多少个case是有问题的,我们无法一次性把问题修复好,照成我们工作量变大,并且效率变低,那么我们该如何改进这个情况呢?
我们知道问题出在t.Fatalf,那么我们可不可以即打印出错误信息又不让程序中断呢?答案是: 可以! 我们使用f.Errorf替换f.Fatalf
可是…..
如果某个case出现了panic同样会导致整个程序中断,所以这种方式治标不治本。那么我们该如何改进呢? Go 1.7 开始支持了 sub test。 下面我们就按照Sub Test的写法进行修改:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
tests := map[string]struct {
input string
sep string
want []string
}{
"simple": {input: "a/b/c", sep: "/", want: []string{"a", "b", "c"}},
"trailing sep": {input: "a/b/c/", sep: "/", want: []string{"a", "b", "c"}},
"wrong sep": {input: "a/b/c", sep: ",", want: []string{"a/b/c"}},
"no sep": {input: "abc", sep: "/", want: []string{"abc"}},
}
for name, tc := range tests {
t.Run(name, func(t *testing.T) {
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(tc.want, got) {
t.Fatalf("expected: %v , got %v", tc.want, got)
}
})
}
}
通过t.Run的源码我们看到:1
2
3
4
5func (t *T) Run(name string, f func(t *T)) bool {
...
go tRunner(t, f)
...
}
其实会诊对每个case启动一个goroutine, 所以其中一个出现了panic不会影响其他的case执行。
上面这种形态就是目前我们进行单元测试的最佳实践了。
高级
理论知识
外部依赖
外部依赖是指我们的函数需要调用其他的函数,外部依赖有可能涉及到一些数据依赖,网络依赖等。关于单元测试中如何解决外部依赖的问题, 常用的方法是: Test Double(测试替身), 而它也分很多种:
- Dummy objects are passed around but never actually used. Usually they are just used to fill parameter lists.
- Fake objects actually have working implementations, but usually take some shortcut which makes them not suitable for production (an in memory database is a good example).
- Stubs provide canned answers to calls made during the test, usually not responding at all to anything outside what’s programmed in for the test.
- Spies are stubs that also record some information based on how they were called. One form of this might be an email service that records how many messages it was sent.
- Mocks are what we are talking about here: objects pre-programmed with expectations which form a specification of the calls they are expected to receive.
看上去有点儿头大,分这么多类型而且他们的接线感觉也比较模糊,为了便于理解我们不对这些概念做过多的解读,我们后面把所有我们的工作都看做是Mock
编写可测试代码
函数要短小
函数的第一规则是要短小。第二条规则是还要短小 ———— 《代码整洁之道》
至于如何才算短小,一般建议是不超过100行,也就是显示器一屏所显示的行数。
函数越短小那么单元测试的编写就越简单。
函数功能要单一
函数应该做一件事。做好这件事。只做一件事。 ————–《代码整洁之道》
一个函数做的事情越少其逻辑越简单,难么对应的单元测试也就越简单。
减少外部依赖
这里要明确的是我们要测试的是自己的函数而不是调用的函数,所以我们应该把中重点放到自己的函数上,至于外部依赖的函数越少越好,因为每个外部依赖都增加了我们单元测试的不确定性。
依赖模块要方便 Mock
为了专注我们自己模块的测试,对于外部的模块我们一般都会使用Mock的方法, 所以依赖模块如果好Mock的话测试起来就会方便很多,反之会很麻烦。
方便依赖注入
一般我们Mock是通过依赖注入的方式,这种方式可以方便的更改依赖的对象的实现,而依赖注入的方式有好几种:
- 通过变量赋值
- 通过参数传递
- 通过Set/Get方法
一个外部依赖的例子
一个User包, 有一个通过uid获取分数score的方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30package user
import (
"strconv"
"github.com/go-redis/redis"
)
func Score(uid int) (int, error) {
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
_, err := client.Ping().Result()
if err != nil {
return -1, err
}
val, err := client.Get(strconv.Itoa(uid)).Result()
if err == redis.Nil {
return -1, nil
}
if err != nil {
return -1, err
}
return strconv.Atoi(val)
}
一个Class包,通过调用user.Score方法获取分数,根据分数给这个用户一个等级:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25package class
import (
"user"
)
func UserLevel(uid int) string {
score, err := user.Score(uid)
if err != nil {
return "E"
}
switch {
case score < 0:
return "N"
case score <= 60:
return "C"
case score <= 90:
return "B"
case score <= 100:
return "A"
default:
return "W"
}
}
现在我们要给UserLevel写单元测试,该怎么写呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28package class
import (
"testing"
)
func TestUserLevel(t *testing.T) {
tests := map[string]struct {
input int
want string
}{
"not found user": {input: 1, want: "N"},
"C level": {input: 2, want: "C"},
"B level": {input: 3, want: "B"},
"A level": {input: 4, want: "A"},
"Got Error": {input: 5, want: "E"},
"Wrong Score": {input: 5, want: "W"},
}
for name, tc := range tests {
got := UserLevel(tc.input)
t.Run(name, func(t *testing.T) {
if tc.want != got {
t.Fatalf("expected: %s, got %s", tc.want, got)
}
})
}
}
运行单元测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$ go test
--- FAIL: TestUserLevel (0.02s)
--- FAIL: TestUserLevel/not_found_user (0.00s)
class_test.go:24: expected: N, got E
--- FAIL: TestUserLevel/C_level (0.00s)
class_test.go:24: expected: C, got E
--- FAIL: TestUserLevel/B_level (0.00s)
class_test.go:24: expected: B, got E
--- FAIL: TestUserLevel/A_level (0.00s)
class_test.go:24: expected: A, got E
--- FAIL: TestUserLevel/Wrong_Score (0.00s)
class_test.go:24: expected: W, got E
FAIL
exit status 1
FAIL class 0.023s
可以看到除了Got Error运行成功,其他的都失败了,因为我们本地并没有开启redis服务,所以是连不上的。如果我们要让这个测试用例通过,显然我们不能真的开启一个redis的服务,我们需要对user.Score进行Mock
Mock框架
go中mock的支持也有很多种:
- github.com/golang/mock
- github.com/bouk/monkey
- github.com/smartystreets/goconvey
- github.com/stretchr/testify
- github.com/prashantv/gostub
每个框架都有自己的用法, 这里我那github.com/bouk/monkey来举例子, 改造一下我们的单元测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51package class
import (
"errors"
"testing"
"bou.ke/monkey"
"user"
)
func TestUserLevel(t *testing.T) {
tests := map[string]struct {
input int
want string
}{
"not found user": {input: 1, want: "N"},
"C level": {input: 2, want: "C"},
"B level": {input: 3, want: "B"},
"A level": {input: 4, want: "A"},
"Got Error": {input: 5, want: "E"},
"Wrong Score": {input: 6, want: "W"},
}
monkey.Patch(user.Score, mockScore)
for name, tc := range tests {
got := UserLevel(tc.input)
t.Run(name, func(t *testing.T) {
if tc.want != got {
t.Fatalf("expected: %s, got %s", tc.want, got)
}
})
}
}
func mockScore(uid int) (int, error) {
switch uid {
case 1:
return -1, nil
case 2:
return 10, nil
case 3:
return 70, nil
case 4:
return 95, nil
case 5:
return -1, errors.New("something was error")
case 6:
return 130, nil
}
return -1, nil
}
运行测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17$ go test -v
=== RUN TestUserLevel
=== RUN TestUserLevel/not_found_user
=== RUN TestUserLevel/C_level
=== RUN TestUserLevel/B_level
=== RUN TestUserLevel/A_level
=== RUN TestUserLevel/Got_Error
=== RUN TestUserLevel/Wrong_Score
--- PASS: TestUserLevel (0.00s)
--- PASS: TestUserLevel/not_found_user (0.00s)
--- PASS: TestUserLevel/C_level (0.00s)
--- PASS: TestUserLevel/B_level (0.00s)
--- PASS: TestUserLevel/A_level (0.00s)
--- PASS: TestUserLevel/Got_Error (0.00s)
--- PASS: TestUserLevel/Wrong_Score (0.00s)
PASS
ok class 0.014s
面相接口编程
前面通过Mock框架我们可以在测试的时候替换原来的实现,这样就可以很方便的进行单元测试了,但是这种代码的实现方式其实并不符合面相对象设计的原则, 下面提出两个问题:
- 如果我们不依赖
Mock框架该如何mock? - 如果有一天我们不从
redis获取数据,而是要从mysql获取数据了,怎么改?直接改Score函数么?那么如果有一天又要从redis获取数据呢?或者有的调用者是从redis获取数据,有的是从mysql获取数据怎么办?
可见上面的方式不太灵活,面对复杂多变的需求无法很好的满足。这时就要求我们改用面相接口编程, 下面是我们使用面相接口编程的方式改进了上面的实现:user包增加了一个User接口,这个接口有一个函数Score, 然后定义了一个defaultUser, 并且实现了Score函数,最后定一个New函数向外输出这个defaultUser:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40package user
import (
"strconv"
"github.com/go-redis/redis"
)
type User interface {
Score(int) (int, error)
}
func New() User {
return defaultUser{}
}
type defaultUser struct{}
func (defaultUser) Score(uid int) (int, error) {
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
_, err := client.Ping().Result()
if err != nil {
return -1, err
}
val, err := client.Get(strconv.Itoa(uid)).Result()
if err == redis.Nil {
return -1, nil
}
if err != nil {
return -1, err
}
return strconv.Atoi(val)
}
class包调用由原来的通过包直接调用改为了增加一个u变量, 然后调用u.Score来获取信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package class
import (
"user"
)
var u = user.New()
func UserLevel(uid int) string {
score, err := u.Score(uid)
if err != nil {
return "E"
}
switch {
case score < 0:
return "N"
case score <= 60:
return "C"
case score <= 90:
return "B"
case score <= 100:
return "A"
default:
return "W"
}
}
class_test不再依赖mock框架,而是实现了自己的User接口mockUser,替换了user包的defaultUser:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50package class
import (
"errors"
"testing"
)
func TestUserLevel(t *testing.T) {
tests := map[string]struct {
input int
want string
}{
"not found user": {input: 1, want: "N"},
"C level": {input: 2, want: "C"},
"B level": {input: 3, want: "B"},
"A level": {input: 4, want: "A"},
"Got Error": {input: 5, want: "E"},
"Wrong Score": {input: 6, want: "W"},
}
u = mockUser{}
for name, tc := range tests {
got := UserLevel(tc.input)
t.Run(name, func(t *testing.T) {
if tc.want != got {
t.Fatalf("expected: %s, got %s", tc.want, got)
}
})
}
}
type mockUser struct{}
func (mockUser) Score(uid int) (int, error) {
switch uid {
case 1:
return -1, nil
case 2:
return 10, nil
case 3:
return 70, nil
case 4:
return 95, nil
case 5:
return -1, errors.New("something was error")
case 6:
return 130, nil
}
return -1, nil
}
运行单元测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17$ go test -v
=== RUN TestUserLevel
=== RUN TestUserLevel/not_found_user
=== RUN TestUserLevel/C_level
=== RUN TestUserLevel/B_level
=== RUN TestUserLevel/A_level
=== RUN TestUserLevel/Got_Error
=== RUN TestUserLevel/Wrong_Score
--- PASS: TestUserLevel (0.00s)
--- PASS: TestUserLevel/not_found_user (0.00s)
--- PASS: TestUserLevel/C_level (0.00s)
--- PASS: TestUserLevel/B_level (0.00s)
--- PASS: TestUserLevel/A_level (0.00s)
--- PASS: TestUserLevel/Got_Error (0.00s)
--- PASS: TestUserLevel/Wrong_Score (0.00s)
PASS
ok class 0.005s
下面再来看上面提出的两个问题:
- 如果我们不依赖
Mock框架该如何mock?
答: 根据上面的实现可以看到,我们没有借助任何框架同样完成了Mock的效果 - 如果有一天我们不从
redis获取数据,而是要从mysql获取数据了,怎么改?直接改Score函数么?那么如果有一天又要从redis获取数据呢?或者有的调用者是从redis获取数据,有的是从mysql获取数据怎么办?
答: 由于面相接口编程,我们可以在user中增加一个实例实现从mysql获取数据的方法,调用者可以根据需求选择不同的实例,而且如果调用者对这个数据来源有自己的需求,甚至可以自己实现这个接口。
工厂方法
上面的实现我们可以看到每次调用var u = user.New()都会新建一个defaultUser对象,对于有些需要共享defaultUser状态的情况下,例如defaultUser中有一个常驻内存共享的数据, 我们在多个包调用的时候其实那得是不同的对象,为了共享这个数据我们把user.New改成下面的实现:1
2
3
4
5var du = defaultUser{}
func New() User {
return du
}
这样每次返回的其实都是同一个defaultUser。
更方便的调用
上面我们看出,修改为面相接口编程后我们需要通过依赖注入传递对象,但是这样会对调用者照成麻烦,我们是否可以在优化一下呢?
我们在user中增加一个函数:1
2
3func Score(uid int) (int, error) {
return du.Score(uid)
}
这样我们就可以通过user.Score调用du.Score函数了,所以class.go的实现可以改为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25package class
import (
"user"
)
func UserLevel(uid int) string {
score, err := user.Score(uid)
if err != nil {
return "E"
}
switch {
case score < 0:
return "N"
case score <= 60:
return "C"
case score <= 90:
return "B"
case score <= 100:
return "A"
default:
return "W"
}
}
看上去不错,但是我们如何进行依赖注入呢?不然单元测试使用的是默认实现,我们没办法做单元测试了。前面其实我们提过依赖注入的方式有一个Get/Set方式,我们可以再修改一下user包:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55package user
import (
"strconv"
"github.com/go-redis/redis"
)
type User interface {
Score(int) (int, error)
}
func Score(uid int) (int, error) {
if definedUser != nil {
return definedUser.Score(uid)
}
return du.Score(uid)
}
var definedUser User
func SetUser(u User) {
definedUser = u
}
var du = defaultUser{}
func New() User {
return du
}
type defaultUser struct{}
func (defaultUser) Score(uid int) (int, error) {
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
_, err := client.Ping().Result()
if err != nil {
return -1, err
}
val, err := client.Get(strconv.Itoa(uid)).Result()
if err == redis.Nil {
return -1, nil
}
if err != nil {
return -1, err
}
return strconv.Atoi(val)
}
class不用修改,class_test修改为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52package class
import (
"errors"
"testing"
"user"
)
func TestUserLevel(t *testing.T) {
tests := map[string]struct {
input int
want string
}{
"not found user": {input: 1, want: "N"},
"C level": {input: 2, want: "C"},
"B level": {input: 3, want: "B"},
"A level": {input: 4, want: "A"},
"Got Error": {input: 5, want: "E"},
"Wrong Score": {input: 6, want: "W"},
}
user.SetUser(mockUser{})
for name, tc := range tests {
got := UserLevel(tc.input)
t.Run(name, func(t *testing.T) {
if tc.want != got {
t.Fatalf("expected: %s, got %s", tc.want, got)
}
})
}
}
type mockUser struct{}
func (mockUser) Score(uid int) (int, error) {
switch uid {
case 1:
return -1, nil
case 2:
return 10, nil
case 3:
return 70, nil
case 4:
return 95, nil
case 5:
return -1, errors.New("something was error")
case 6:
return 130, nil
}
return -1, nil
}
我们通过user.SetUser方法用自己的实现替换了之前默认的实现,这样我们就可以方便的进行单元测试了。
运行单元测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17$ go test -v
=== RUN TestUserLevel
=== RUN TestUserLevel/Wrong_Score
=== RUN TestUserLevel/not_found_user
=== RUN TestUserLevel/C_level
=== RUN TestUserLevel/B_level
=== RUN TestUserLevel/A_level
=== RUN TestUserLevel/Got_Error
--- PASS: TestUserLevel (0.00s)
--- PASS: TestUserLevel/Wrong_Score (0.00s)
--- PASS: TestUserLevel/not_found_user (0.00s)
--- PASS: TestUserLevel/C_level (0.00s)
--- PASS: TestUserLevel/B_level (0.00s)
--- PASS: TestUserLevel/A_level (0.00s)
--- PASS: TestUserLevel/Got_Error (0.00s)
PASS
ok class 0.011s
在大多数情况下,我们都是使用的默认实现,只有在我们必须要修改依赖的实现,或者单元测试时才会使用其他的实现,所以为了大多数的场景下调用简单,我们应该尽量使用这种方式来实现。
总结
本文主要回顾了一下关于单元测试的一些理论知识:
- 测试的粒度应该是测试包中的可导出函数
- 测试的原则告诉我们应该是变测试变开发, 相互交替进行
- 测试的目的应该是测试行为,而不是测试具体的实现
关于Go的单元测试可以分为三个阶段:
- 初级阶段: 主要是认识Go的单元测试基本写法,以及如何利用Go的工具链运行单元测试及查看单元测试覆盖率的情况
- 进阶阶段: 主要是举一个单元测试的例子,通过不断改进这个单元测试的写法来告诉我们如何写出更好的单元测试
- 高级阶段: 介绍了如何写出可测试的函数,面对复杂的调用和多变得需求如何利用面相接口编程和依赖注入改进我们的程序的写法
参考
Test-Driven Development By Example
Testing; how, what, why - Dave
TDD, Where Did It All Go Wrong - Lan Cooper
The Three Laws of TDD.
深度解读 - TDD(测试驱动开发)
如何写出优雅的 Golang 代码
单元测试wiki
How to Write Go Code - Testing
Testing Behavior vs. Testing Implementation
Avoid Testing Implementation Details, Test Behaviours
边界条件测试
代码整洁之道
Mocks Aren’t Stubs
TestDouble