$subject = new Subject("Math"); $marcus = new Teacher("Marcus Brasizza"); $rafael = new Student("Rafael"); $vinicius = new Student("Vinicius"); // Include observers in the math Subject $subject->attach($rafael); $subject->attach($vinicius); $subject->attach($marcus); $subject2 = new Subject("English"); $renato = new Teacher("Renato"); $fabio = new Student("Fabio"); $tiago = new Student("tiago"); // Include observers in the english Subject $subject2->attach($renato); $subject2->attach($vinicius); $subject2->attach($fabio); $subject2->attach($tiago); // Remove the instance "Rafael from subject" $subject->detach($rafael); // Notify both subjects $subject->notify(); $subject2->notify(); echo"First Subject <br />"; echo"<pre>"; print_r($subject->GET_log()); echo"</pre>"; echo"<hr>"; echo"Second Subject <br />"; echo"<pre>"; print_r($subject2->GET_log()); echo"</pre>";
[0] => Subject Math was included [1] => The Student Rafael was included [2] => The Student Vinicius was included [3] => The Teacher Marcus Brasizza was included [4] => The Student Rafael was removed [5] => Comes from Vinicius: I'm a student of Math [6] => Comes from Marcus Brasizza: I teach in Math ) //Second Subject Array ( [0] => Subject English was included [1] => The Teacher Renato was included [2] => The Student Vinicius was included [3] => The Student Fabio was included [4] => The Student tiago was included [5] => Comes from Renato: I teach in English [6] => Comes from Vinicius: I'm a student of English [7] => Comes from Fabio: I'm a student of English [8] => Comes from tiago: I'm a student of English )
[0] => Subject Math was included [1] => The Student Rafael was included [2] => The Student Vinicius was included [3] => The Teacher Marcus Brasizza was included [4] => The Student Rafael was removed [5] => Comes from Vinicius: I'm a student of Math [6] => Comes from Marcus Brasizza: I teach in Math )
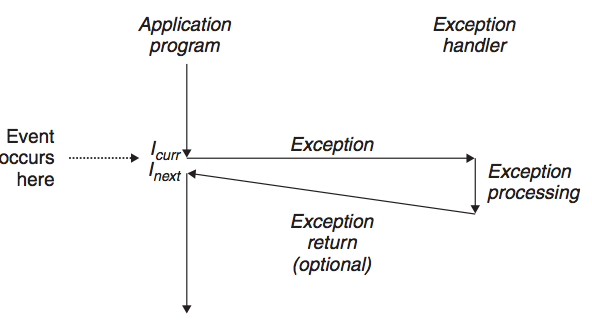
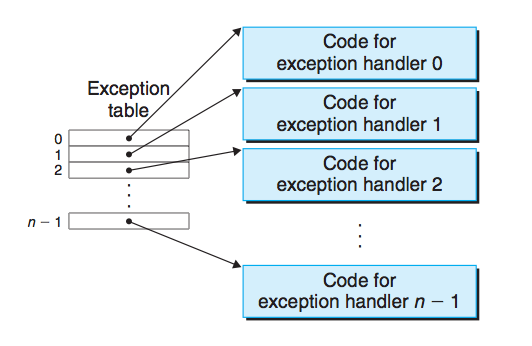
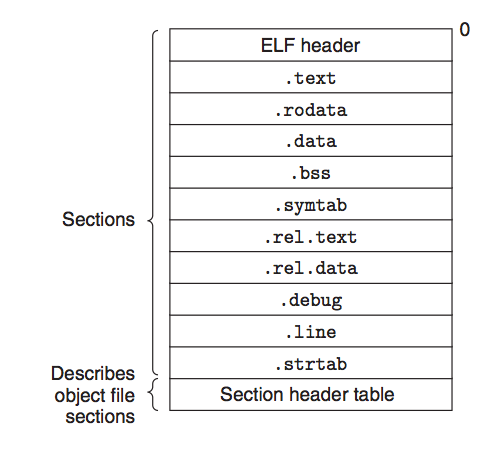
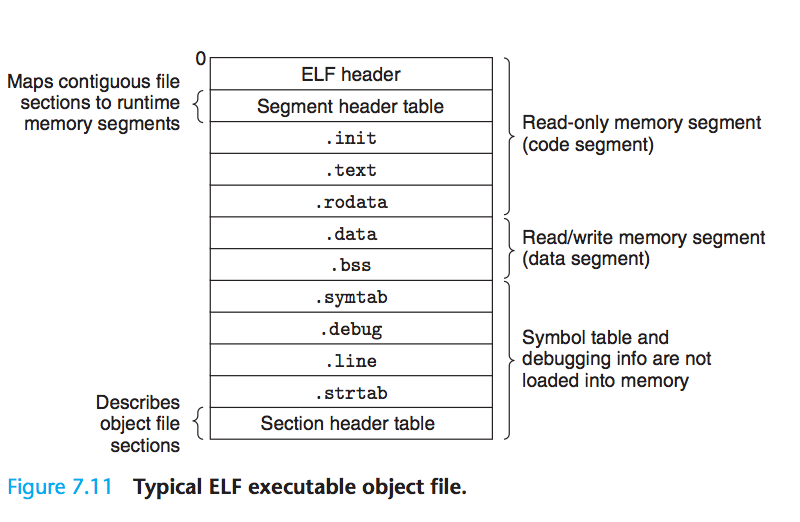
程序运行的顺序是根据程序计数器(PC)的值而定的,PC从一个地址到另一个地址的过渡称为控制转移(control transfer),这样的控制转移序列叫做处理器的控制流(flow of control或 control flow)。一般如果PC是按照顺序地址进行过渡的,控制流是一个平滑的序列,但是有些情况下PC是来回跳转的,这些突变称为异常控制流(Exceptional Control Flow 简称EFC),EFC发生在计算机系统的各个层次。本章主要分析这种异常控制流。