# 3 使用命令替换[list] for arg in `command` do commands... done
# 4 使用C风格 for ((a=1; a <= LIMIT ; a++)) do commands... done
# 5 while while [condition] #与条件判断的condition一样 do commands... done
# 6 until 类似于C的do...while until [condition] do commands... done
# 7 嵌套循环与控制 for a in [list] do for b in [list] do for c in [list] do break 2 #带层参数:退出从本层算,往外到第二层的循环 done for d in [list] do continue #不带层参数:继续本层的循环 done break #不带层参数:退出本层循环 done done
分支
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# case case "$variable" in $condition1 ) command...;; $condition2 ) command...;; ... $conditionn ) command...;; *) command ...;; #相当于default esac
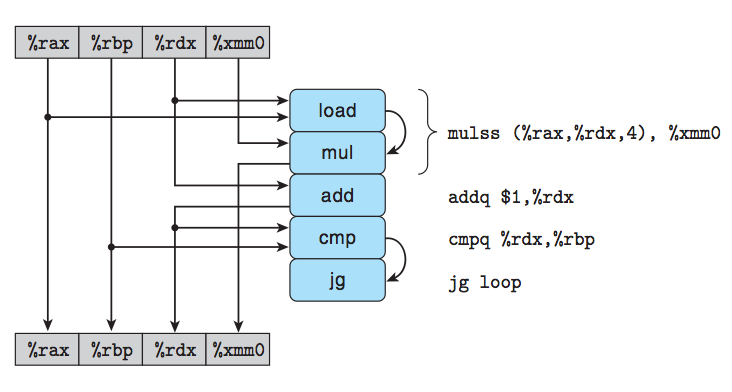
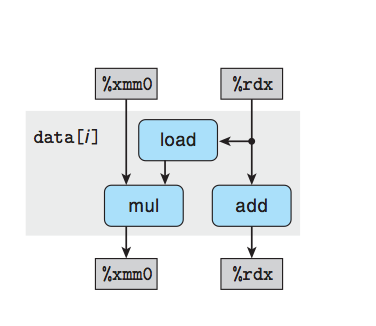
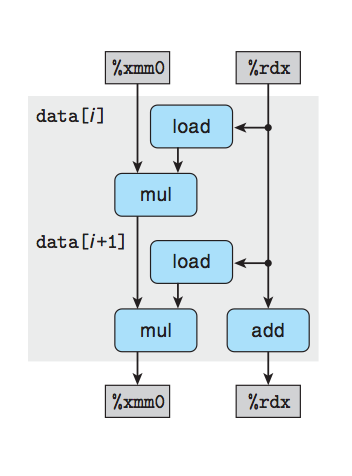
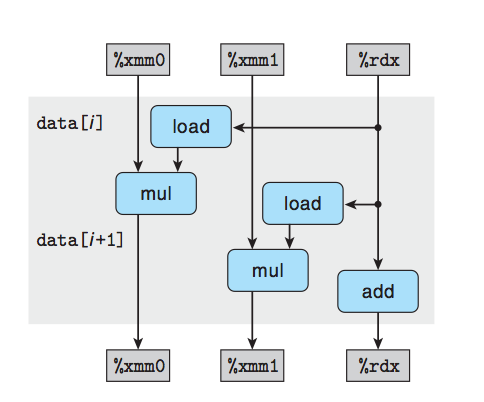
引入度量标准每元素的周期数(Cycles Per Element, CPE),作为一种表示程序性能并指导我们改进代码的方法。 处理器活动的顺序是由时钟控制的,时钟提供了某个频率的规律信号,通常用千兆赫兹(GHz)。就是我们常说的CPU的运行频率。时钟周期就是时钟频率的倒数。
程序示例
举例说明程序优化的效果,这里写出最后的运行函数:
1 2 3 4 5 6 7 8 9
void combine1(vec_ptr v, data_t *dest) { long int i; *dest = IDENT; for (i=0; i < vec_length(v); i++){ data_t val; get_vec_element(v, i, &val); *dest = *dest OP val; }
MERGE表比MyISAM表需要更多的文件描述。 If 10 clients are using a MERGE table that maps to 10 tables, the server uses (10 × 10) + 10 file descriptors. (10 data file descriptors for each of the 10 clients, and 10 index file descriptors shared among the clients.),这个也不太明白。
class PlantUMLFile < StaticFile def write(dest) true end end
class PlantUMLBlock < Liquid::Block def render(context) site = context.registers[:site] code = @nodelist.join source = "<center>" source += "<img alt='this is uml image' uml='"+code+"'>" source += "</center>" source end end end