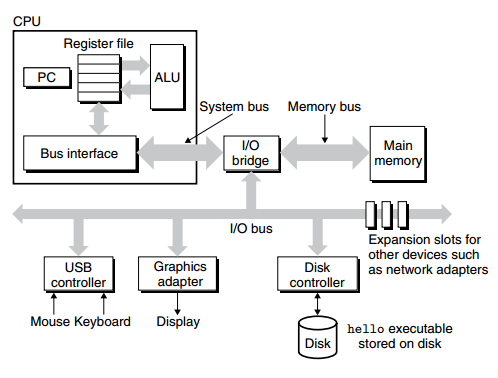
前面讲了不少关于Rest的知识,但是现在大部分都是RPC或者REST-RPC混合的模式,这种并不是纯粹的Rest架构。本章就是为了介绍REST架构及面向资源的服务到底是什么样的。
资源
Amazon S3为例子进行介绍。S3提供SOAP和REST两种服务方式,一个桶就是一个放置资源的仓库,桶列表就是仓库的列表,一个对象就是放置到仓库里的一个资源。S3的资源及其方法如下:
| GET | HEAD | PUT | DELETE | |
|---|---|---|---|---|
| 桶列表 | 列出所有桶 | - | - | - |
| 一个桶 | 列出桶里的对象 | - | 创建桶 | 删除桶 |
| 一个对象 | 获取对象的值及元数据 | 获取对象的元数据 | 设置对象的值及元数据 | 删除对象 |
从表中可以看出每个方法的作用都是名副其实的。
HTTP相应代码
利用HTTP响应代码是REST架构的另一个标志象征。程序根据HTTP响应代码来判断响应的内容是正确的还是错误的。
一个S3客户端
下面我们根据S3客户端编写的代码来剖析REST服务。
对桶的操作
获取桶的列表(GET方法):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 桶列表
class BucketList
inlcude Authorized
#获取该用户的所有桶
def get
buckets = []
#向桶列表的URI发送GET请求,并读取返回的XML文档
doc = REXML::Document.new(open(HOST).read)
#对于每个桶...
REXML::XPath.each(doc, "//Bucket/Name") do |e|
#...创建一个Bucket对象,并把它添加到列表中
bucket << Bucket.new(e.text) if e.text
end
return buckets
end
end
保存或更新桶(PUT方法)和删除桶(DELETE方法):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# 一个S3桶
class Bucket
include Authorized
attr_accessor :name
def initialize(name)
@name = name
end
#桶的URI等于服务的根URI加上桶名
def uri
HOST + URI.escape(name)
end
#在S3上保存这个桶
#类似于在数据库里保存对象的ActiveRecord::Base#save.
def put(acl_policy=nil)
#设置HTTP方法,作为open()的参数
#同时为该桶设置S3访问策略(如果有提供的话)
args = {:method=> :put}
args["x-amz-acl"] =acl_policy if acl_policy
#向该桶的URI发送PUT请求
open(uri, args)
return self
end
#删除该桶
#如果该桶不为空的话,改删除操作将失败
#并返回HTTP响应代码409("Conflict")
def delete
open(uri, :method => :delete)
end
对对象的操作
获取对象(GET方法)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# 获取桶里的全部或部分对象
def get(options={})
#获取该桶的基准URI,并把子集选项
#附加到查询字符串上
uri = uri()
suffix = '?'
#对于用户提供的每个选项...
options.each do |param, value|
#...如果属于某个S3子集选项...
if [:Prefix, :Maker, :Delimiter, :MaxKeys].member? :param
#...把它附加到URI上
uri << suffix << param.to_s << '=' << URI.escape(value)
suffix = '&'
end
end
#现在我们已经构造好了URI,向该URI发送GET请求,
#并读取含有S3对象信息的XML文档
doc = REXML::Document.new(open(uri).read)
there_are_more = REXML::XPath.first(doc, "//IsTruncated").text == "true"
#构建一个S3::Object对象的列表
objects = []
#对于桶里的每个S3对象...
REXML::XPath.each(doc, "//Contents/Key") do |e|
#...构建一个S3:Object对象,并把它添加到列表中
objects << Object.new(self, e.text) if e.text
end
return objects, there_are_more
end
获取对象数据(GET方法)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 跟某个桶关联的一个具有值和元数据的S3对象
class Object
include Authorized
#客户端可以知道对象在哪个桶里
attr_reader :bucket
#客户端可以读写对象的名称
attr_accessor :name
#客户端可以写对象的元数据和值
attr_writer :metadata, :value
def initialize(bucket, name, value=nil, metadata=nil)
@bucket, @name, @value, @metadata = bucket, name, value, metadata
end
#对象的URI等于所在桶的URI加上该对象的名称
def uri
@bucket.uri + '/' + URI.escape(name)
end
获取对象元数据(HEAD方法)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 获取对象的元数据hash
def metadata
#如果没有元数据...
unless @metadata
#向对象的URI发送一个HEAD请求,并从响应的HTTP报头里读取元数据
begin
store_metadata(open(uri, :method => :head).meta)
rescue OpenURI::HTTPError => e
if e.io.status == ["404", "Not Found"]
#假如没有元数据是因为对象不存在,这不算错误
@metadata = {}
else
#其他情况,做错误处理
raise e
end
end
end
return @metadata
end
获取对象数据(GET方法)1
2
3
4
5
6
7
8
9
10
11
12
13# 获取对象的值和元数据
def value
#如果没有值...
unless @value
#向对象的URI发送GET请求
response = opne(uri)
#从相应的HTTP报头里读取元数据
store_metadata(respons.meta) unless @metadata
#从实体主体里读取值
@value = response.read
end
return @value
end
保存对象数据(PUT方法)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 在S3上保存对象
def put(acl_policy=nil)
#以原始元数据的副本开始,或者
#如果没有元数据的话,就以空hash开始。
args = @metadata ? @metadata.cloen :{}
#设置HTTP方法、实体主体及一些另外的HTTP报头
args[:method] = :put
args["x-amz-acl"] = acl_policy if acl_policy
if @value
args["Content-Lenght"] = @value.size.to_s
args[:body] = @value
end
#向对象的URI发送PUT请求
open(uri, args)
return self
end
删除对象数据(DELETE方法)1
2
3
4
5# 删除对象
def delete
#向对象的URI发送DELETE请求
open(uri,:method => :delete)
end
通过上面这些例子的介绍,我们对每个方法的使用都有了一个大致的印象,知道每个方法对应的应用场景。实际的使用过程中是如何把他们关联起来的呢?下面再对它们的应用通过一个例子做一个综合的介绍。
使用S3客户端
1 | # !/usr/bin/ruby -w |
用ActiveResource创建透明的客户端
安装ruby on rails,然后利用rails生成一个创建一个自己的app,根据书里的过程并参考《Ruby On Ralis 3 Toturial》中的例子就可以完成。建立完成后可以在页面中看到notes的操作了,可以增加,编辑,删除note,可以到在views里可以看到这么一段代码:1
<td><%= link_to 'Destroy', note, method: :delete, data: { confirm: 'Are you sure?' } %></td>
ruby中前端是通过method来指定HTTP请求的发送类型的,但是我在web端看到的请求是:1
2
3Request Method:POST
Form Data:
_method:delete
从这里来看ruby并没有在HTTP请求的方法中就变为DELETE,而是在from里传了一个参数,这并不是符合标准的REST架构的。鉴于我对ROR还不了解,现在可能有些不太明白,先看着后面的章节,等了解后再完善本章内容。